This is an updated version of the article originally posted on 29th March 2014 at Programmer’s Ranch. The source code for this article is available at the Gigi Labs BitBucket repository.
In this article, we’re going to learn how we can write text in our window. To do this, we’ll use the SDL_ttf library. Setting it up is almost identical to how we set up SDL_image in “Loading Images in SDL2 with SDL_image“. You need to download the Visual C++ development libraries from the SDL_ttf homepage:

Then, extract the lib and include folders over the ones you have in your sdl2 folder. You should end up with an SDL_ttf.h in your include folder, and you should get SDL2_ttf.lib and a few DLLs including SDL_ttf.dll in your lib\x86 and lib\x64 folders.
In your Linker -> Input, you’ll then need to add SDL2_ttf.lib:

Good. Now, let’s start with the following code which is a modified version of the code from about halfway through “Displaying an Image in an SDL2 Window“:
#include <SDL.h>
int main(int argc, char ** argv)
{
bool quit = false;
SDL_Event event;
SDL_Init(SDL_INIT_VIDEO);
SDL_Window * window = SDL_CreateWindow("SDL_ttf in SDL2",
SDL_WINDOWPOS_UNDEFINED, SDL_WINDOWPOS_UNDEFINED, 640,
480, 0);
SDL_Renderer * renderer = SDL_CreateRenderer(window, -1, 0);
while (!quit)
{
SDL_WaitEvent(&event);
switch (event.type)
{
case SDL_QUIT:
quit = true;
break;
}
}
SDL_DestroyRenderer(renderer);
SDL_DestroyWindow(window);
SDL_Quit();
return 0;
}
The first thing we need to do in order to use SDL_ttf is include the relevant header file:
#include <SDL_ttf.h>
Then, we initialise the SDL_ttf library right after we call SDL_Init():
TTF_Init();
…and we clean it up just before we call SDL_Quit():
TTF_Quit();
Right after we initialise our renderer, we can now load a font into memory:
TTF_Font * font = TTF_OpenFont("arial.ttf", 25);
TTF_OpenFont() takes two parameters. The first is the path to the TrueType Font (TTF) that it needs to load. The second is the font size (in points, not pixels). In this case we’re loading Arial with a size of 25.
A font is a resource like any other, so we need to free the resources it uses near the end:
TTF_CloseFont(font);
We can now render some text to an SDL_Surface using TTF_RenderText_Solid(). which takes the font we just created, a string to render, and an SDL_Color which we are passing in as white in this case:
SDL_Color color = { 255, 255, 255 };
SDL_Surface * surface = TTF_RenderText_Solid(font,
"Welcome to Gigi Labs", color);
We can then create a texture from this surface as we did in “Displaying an Image in an SDL2 Window“:
SDL_Texture * texture = SDL_CreateTextureFromSurface(renderer, surface);
And yet again, we should not forget to release the resources we just allocated near the end, so let’s do that right away:
SDL_DestroyTexture(texture); SDL_FreeSurface(surface);
Now all we need is to actually render the texture. We’ve done this before; just add the following just before the end of your while loop:
SDL_RenderCopy(renderer, texture, NULL, NULL); SDL_RenderPresent(renderer);
Okay, now before we actually run this program, we need to put our Arial TTF font somewhere where our program can find it. Go to C:\Windows\Fonts, and from there copy the Arial font into the Debug folder where your executable is compiled. This will result in several TTF files, although we’re only going to use arial.ttf. We will also need the usual SDL2.dll, along with the SDL_ttf DLLs (libfreetype-6.dll, zlib1.dll and SDL2_ttf.dll):

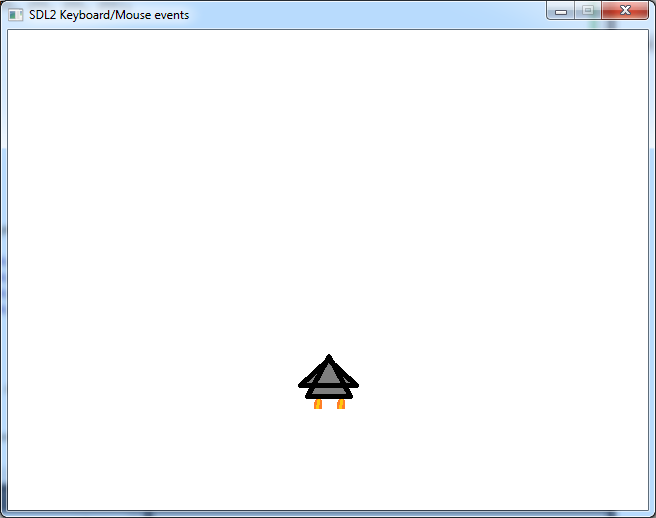
Great, now let’s admire the fruit of our work:

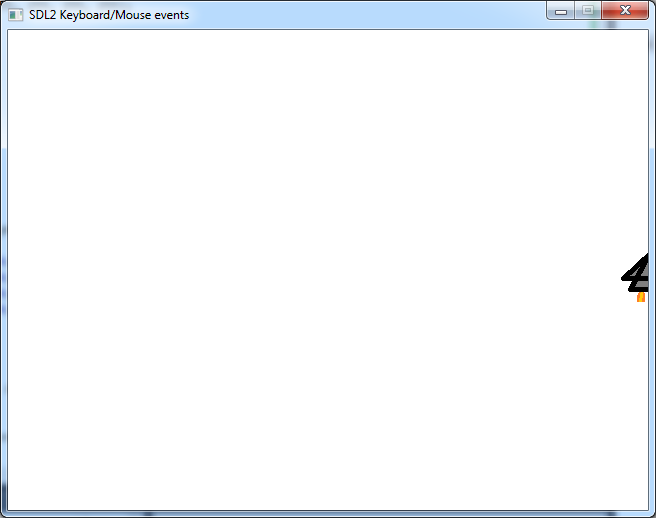
Nooooooooooooooo! This isn’t quite what we were expecting, right? This is happening because the texture is being stretched to fill the contents of the window. The solution is to supply the dimensions occupied by the text in the dstrect parameter of SDL_RenderCopy() (as we did in “Displaying an Image in an SDL2 Window“). But how can we know these dimensions?
If you check out Will Usher’s SDL_ttf tutorial, you’ll realise that a function called SDL_QueryTexture() can give you exactly this information (and more). So before our while loop, let’s add the following code:
int texW = 0;
int texH = 0;
SDL_QueryTexture(texture, NULL, NULL, &texW, &texH);
SDL_Rect dstrect = { 0, 0, texW, texH };
Finally, we can pass dstrect in our call to SDL_RenderCopy():
SDL_RenderCopy(renderer, texture, NULL, &dstrect);
Let’s run the program now:

Much better! 🙂
In this article, we learned how to use the SDL_ttf to render text using TTF fonts in SDL2. Using the SDL_ttf library in a project was just the same as with SDL_image. To actually use fonts, we first rendered text to a surface, then passed it to a texture, and finally to the GPU. We used SDL_QueryTexture() to obtain the dimensions of the texture, so that we could render the text in exactly as much space as it needed. We also learned how we can set up our project to use the same path regardless of whether we’re running from Visual Studio or directly from the executable.