In this article, we’re going to create a simple Console Application that feels a little bit like Redis. The intention is simply to illustrate what you can do with Redis, not to create anything serious. For this reason, the code will be greatly simplified: we’ll have only a subset of Redis commands, no multithreading, no client/server code, (almost) no parameter validation, and no architecture whatsoever.
Introduction
Redis is a key-value store. You can think of it as a dictionary. In its simplest sense, it could be represented like this:
var store = new Dictionary<string, string>();
However, values in Redis can be more than just strings. In fact, Redis currently supports five main data types:
- Strings
- Lists
- Hashes
- Sets
- Sorted Sets
Since in .NET these data types don’t share a common interface, we will be representing our values as plain objects:
var store = new Dictionary<string, object>();
This will result in some unfortunate type checking code, but this is necessary in this case. Maintaining a separate dictionary per type is not feasible since keys must be globally unique (i.e. you can’t use the same key for a list and a hash).
Note also how the use of a dictionary as an in-memory store means we aren’t persisting anything to disk. This might seem to be an oversimplification, but Redis’ default configuration is actually to store data only in memory. It does support persistence if you need it, but we won’t go there.
Redis supports a simple protocol which feels a bit like issuing commands in a command line if you use something like IMAPTalk. Thus, in our Console Application, we’ll use the following code to simulate Redis’ command processing logic:
string input = string.Empty;
while (true)
{
input = Console.ReadLine();
if (!string.IsNullOrEmpty(input))
{
var tokens = input.Split(); // split the input into words or tokens
if (tokens.Length >= 1)
{
string command = tokens.First().ToLowerInvariant();
try
{
switch(command)
{
// TODO command handling code goes here
default:
Console.WriteLine("Unrecognized command.");
break;
}
}
catch (Exception)
{
Console.WriteLine("Error!");
}
}
}
else
Console.WriteLine("Invalid command.");
}
The above code just accepts input, checks what the command is, and takes action accordingly. In the next sections, we’ll replace that TODO with code to actually handle some of the commands.
Strings
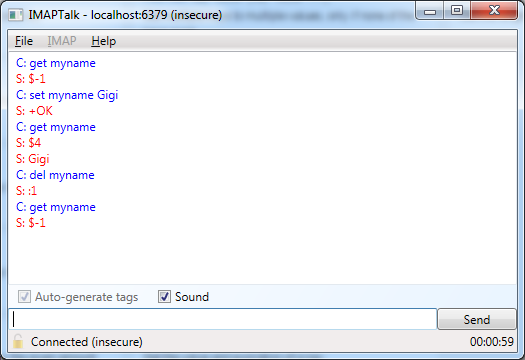
The simplest data type in Redis is the string. You can easily assign a value to a key using the SET command, and then retrieve that value using the GET command, as shown above. The SET command is just a matter of assigning the value in the dictionary:
case "set":
{
string key = tokens[1];
string value = tokens[2];
store[key] = value;
Console.WriteLine("Done.");
}
break;
The GET command similarly involves basic retrieval from the dictionary, but we also need to cater for non-existent keys, and values that are not strings:
case "get":
{
string key = tokens[1];
if (store.ContainsKey(key))
{
var value = store[key] as string;
if (value != null)
Console.WriteLine(value);
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
We can also support key removal using the DEL command. Again, this is a simple operation against the dictionary:
case "del":
{
string key = tokens[1];
store.Remove(key);
Console.WriteLine("Done.");
}
break;
We can now test our three basic string commands:

Lists
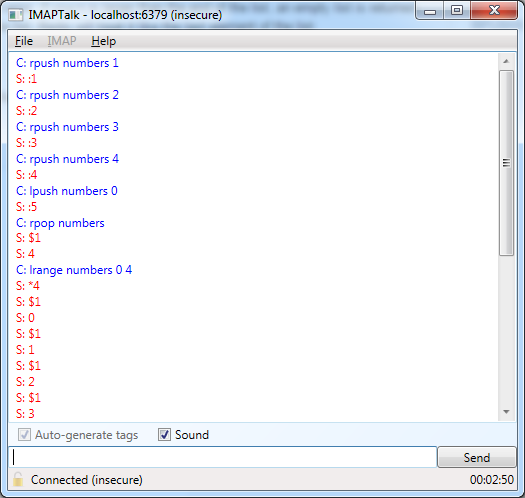
Redis also supports Lists. You can use the LPUSH and RPUSH commands to add an item to the beginning or end of a list respectively – allowing you to easily use the list as a stack or a queue as well. These operations also automatically create the list if it doesn’t already exist.
Here’s how we can implement LPUSH:
case "lpush":
{
string key = tokens[1];
string value = tokens[2];
List<string> list = null;
// create/get list
if (!store.ContainsKey(key))
{
list = new List<string>();
store[key] = list;
}
else
list = store[key] as List<string>;
// insert new value in list
if (list != null)
{
list.Insert(0, value);
Console.WriteLine("Done");
}
else
Console.WriteLine("Invalid data type!");
}
break;
The first thing we do here is retrieve the list we’re going to work with. If it doesn’t exist, we create it. We can then proceed to insert the new item into the list – in this case using List<T>.Insert() to put the item at the beginning of the list.
Note that in Redis, LPUSH actually supports insertion of multiple items with the same command. I’m not doing that here to keep things as simple as possible.
RPUSH is pretty much the same thing, except that you call List<T>.Add() instead of .Insert(), so that the new item ends up at the end of the list.
To remove items from the list, we’ll implement LPOP and RPOP, which remove items from the beginning and end of the list respectively. Here’s LPOP:
case "lpop":
{
string key = tokens[1];
if (store.ContainsKey(key))
{
var list = store[key] as List<string>;
if (list != null)
{
if (list.Count > 0)
{
Console.WriteLine(list.First());
list.RemoveAt(0);
}
else
Console.WriteLine("Empty!");
}
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
Aside from all the validity checks, all we’re doing here is returning the first item in the list, and then removing it. If there are no items in the list, we simply return “Empty!”.
For RPOP, the only difference is that we retrieve and remove the last item instead:
Console.WriteLine(list.Last());
list.RemoveAt(list.Count - 1);
Finally, we need something that can retrieve items in the list (without removing them). For this we have LRANGE, which retrieves a specified range of items (e.g. item #2 till item #4) from the beginning of the list. Indices may be out of range without causing errors; the indices that actually exist will be returned.
Here is the implementation for LRANGE:
case "lrange":
{
string key = tokens[1];
int start = Convert.ToInt32(tokens[2]);
int stop = Convert.ToInt32(tokens[3]);
if (start > stop)
Console.WriteLine("Empty!");
else if (store.ContainsKey(key))
{
var list = store[key] as List<string>;
if (list != null)
{
if (start < 0)
start = 0;
if (stop > list.Count - 1)
stop = list.Count - 1;
var items = list.GetRange(start, stop - start + 1);
if (items.Any())
{
foreach(var item in items)
Console.WriteLine(item);
}
else
Console.WriteLine("Empty!");
}
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
We can now test our list functionality:

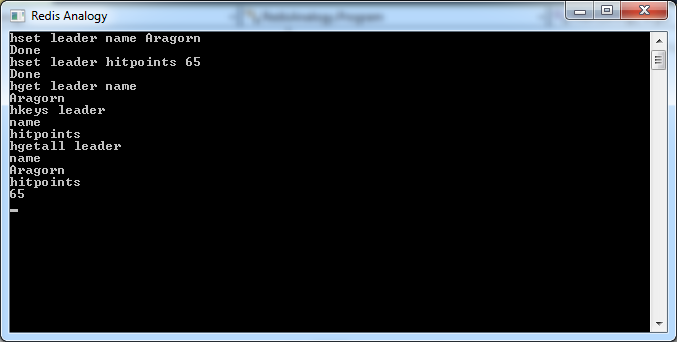
Hashes

Hashes are like dictionaries in themselves. Rather than mapping a value directly to a key, hashes map values onto a field of a key. This allows you to represent objects with a number of attributes (e.g. a customer having separate values for Name, Age, etc).
With HSET, we can assign a value to a key-field, as shown in the screenshot above. Like with Lists, this operation creates the Hash if it doesn’t already exist. Here’s the HSET implementation:
case "hset":
{
string key = tokens[1];
string field = tokens[2];
string value = tokens[3];
Dictionary<string, string> hash = null;
// create/get hash
if (!store.ContainsKey(key))
{
hash = new Dictionary<string, string>();
store[key] = hash;
}
else
hash = store[key] as Dictionary<string, string>;
// set field in hash
if (hash != null)
{
hash[field] = value;
Console.WriteLine("Done");
}
else
Console.WriteLine("Invalid data type!");
}
break;
The code is very similar to that of LPUSH, with the difference that the key now maps to a dictionary (the hash), and the value is assigned to a field on that hash. Think of it as: key -> field -> value.
After using HSET to set a value, we can retrieve it with HGET:
case "hget":
{
string key = tokens[1];
string field = tokens[2];
if (store.ContainsKey(key))
{
var hash = store[key] as Dictionary<string, string>;
if (hash != null)
{
if (hash.ContainsKey(field))
Console.WriteLine(hash[field]);
else
Console.WriteLine("Field not found!");
}
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
HKEYS can be used to retrieve all fields of a hash, given the key:
case "hkeys":
{
string key = tokens[1];
if (store.ContainsKey(key))
{
var hash = store[key] as Dictionary<string, string>;
if (hash != null)
{
foreach (var field in hash.Keys)
Console.WriteLine(field);
}
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
HGETALL, on the other hand, gets all fields of a hash and their corresponding values:
case "hgetall":
{
string key = tokens[1];
if (store.ContainsKey(key))
{
var hash = store[key] as Dictionary<string, string>;
if (hash != null)
{
foreach (var kvp in hash)
{
Console.WriteLine(kvp.Key);
Console.WriteLine(kvp.Value);
}
}
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
Let’s test out our hash functionality:
Sets

Sets in Redis are the mathematical kind: all items in a set are distinct, and multiple sets may be combined via standard set operations (union, intersection and difference).
Use SADD to add one or more items to a set. If the set does not exist, it will be created automatically. Here’s the SADD implementation:
case "sadd":
{
string key = tokens[1];
var members = tokens.Skip(2); // sadd key member [member ...]
HashSet<string> set = null;
// create/get set
if (!store.ContainsKey(key))
{
set = new HashSet<string>();
store[key] = set;
}
else
set = store[key] as HashSet<string>;
// add member to set
if (set != null)
{
foreach (var member in members)
set.Add(member);
Console.WriteLine("Done");
}
else
Console.WriteLine("Invalid data type!");
}
break;
SMEMBERS gives you all the members of the set:
case "smembers":
{
string key = tokens[1];
if (store.ContainsKey(key))
{
var set = store[key] as HashSet<string>;
if (set != null)
{
foreach (var member in set)
Console.WriteLine(member);
}
else
Console.WriteLine("Invalid data type!");
}
else
Console.WriteLine("Key not found!");
}
break;
Standard set operations (union, intersection and difference) require two sets. If either doesn’t exist, these operations will return an empty set rather than giving any kind of error. In Redis, these operations may work on multiple sets at once; but in these examples we’re going to limit the scenario to two sets at a time for the sake of simplicity.
Set union (SUNION) returns all distinct items in the specified sets:
case "sunion":
{
List<HashSet<string>> sets = new List<HashSet<string>>();
var key1 = tokens[1];
var key2 = tokens[2];
// let's assume the keys exist and are the correct type
var set1 = store[key1] as HashSet<string>;
var set2 = store[key2] as HashSet<string>;
// get union
var union = set1.Union(set2);
foreach(var member in union)
Console.WriteLine(member);
}
break;
Set intersection (SINTER) returns those items which are common to both sets:
case "sinter":
{
List<HashSet<string>> sets = new List<HashSet<string>>();
var key1 = tokens[1];
var key2 = tokens[2];
// let's assume the keys exist and are the correct type
var set1 = store[key1] as HashSet<string>;
var set2 = store[key2] as HashSet<string>;
// get intersection
var union = set1.Intersect(set2);
foreach (var member in union)
Console.WriteLine(member);
}
break;
Finally, set difference (SDIFF) returns those items which are in the first set but which are not in the second:
case "sdiff":
{
List<HashSet<string>> sets = new List<HashSet<string>>();
var key1 = tokens[1];
var key2 = tokens[2];
// let's assume the keys exist and are the correct type
var set1 = store[key1] as HashSet<string>;
var set2 = store[key2] as HashSet<string>;
// get intersection
var union = set1.Except(set2);
foreach (var member in union)
Console.WriteLine(member);
}
break;
Let’s test that out:

Sorted Sets
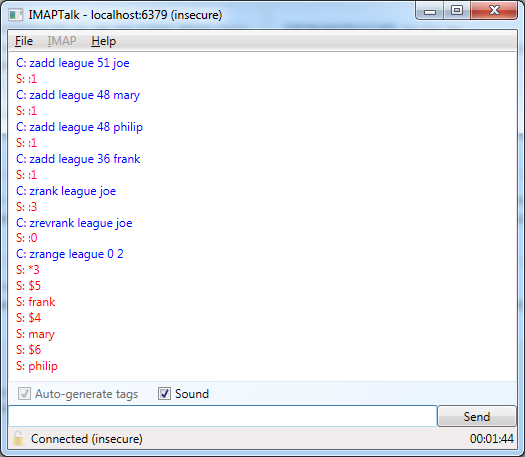
Sorted Sets in Redis are similar to sets, but their members are sorted by a score. This may be used for any kind of ordering from the latest 5 comments to the top 5 posts with most likes.
We can represent a Sorted Set similarly to a hash, using the scheme key -> score -> value. However, there are two main differences from a hash:
- For each score, there may be multiple values; these are sorted lexicographically.
- The scores are ordered (sorted).
The implementation of a Sorted Set in .NET is not as trivial as the other data types, and requires a combination of collections. While a simple representation could be made by combining a SortedDictionary (score -> values) with a SortedSet (distinct and sorted values), this would not allow all Sorted Set commands to be supported (e.g. ZRANK can find the index of a given value, requiring a reverse lookup).
Sorted Sets are thus beyond the scope of this article, which is intended to provide a simple mapping between Redis data types and .NET collections.
Summary
This article explained how the Redis data types work, and showed how some of their operations may be implemented using standard .NET collections. A typical mapping could be:
- Strings – strings
- Lists – Lists
- Hashes – Dictionaries or ConcurrentDictionaries
- Sets – HashSets
- Sorted Sets – a custom data structure
Source Code
The source code for this article is available on BitBucket.



