This article deals with a specific situation. You have a program that is continuously building a data structure from scratch. This data structure takes long (i.e. several seconds) to build, but is continuously accessed by clients. While it is being built, clients will end up retrieving partial data. This article explains how a well-known technique from computer graphics can be used in Redis to address this problem. The full source code is available at BitBucket.
The Problem
Like just about anything, this scenario is best demonstrated with an example. So we’ll first start with some code to set up a client connection to Redis:
private static Lazy<ConnectionMultiplexer> LazyConnection
= new Lazy<ConnectionMultiplexer>(() =>
{
var config = new ConfigurationOptions();
config.EndPoints.Add("localhost:6379");
config.AbortOnConnectFail = false;
return ConnectionMultiplexer.Connect(config);
}
);
public static ConnectionMultiplexer Connection
{
get
{
return LazyConnection.Value;
}
}
The code above is based on the feedback I received from this StackOverflow question and is the proper way to get a connection set up using StackExchange.Redis. You’ll need to install the StackExchange.Redis package via NuGet before you can use this code.
Our actual program code is extremely simple. We establish a connection (via the property above) and then continuously call a method that populates our data structure:
static void Main(string[] args)
{
var connection = Connection;
var database = connection.GetDatabase(0);
while (true)
PopulateAwesomeCompanies(database);
}
We use this infinite loop because the nature of the data may be dynamic, for example items may be removed, and it may be hard to keep track of them. So the data structure is simply rebuilt regularly.
For this simple example, our data structure is going to be a Redis sorted set that stores the most awesome companies to work for, sorted by awesomeness. Here is the data we’re going to be using:
private static string[] companies = new string[]
{
"Google",
"Apple",
"Amazon",
"GFI",
"Blizzard",
"IBM"
};
private static int[] companyScores = new int[] { 95, 15, 80, 0, 100, 56 };
The method that builds the data structure is also very simple. It starts off by erasing the existing data, and then for each company, it calculates their awesomeness (simulated by a simple delay) and adds them to the sorted set:
public static void PopulateAwesomeCompanies(IDatabase database)
{
var key = "awesomecompanies";
Console.WriteLine("Starting afresh...");
database.KeyDelete(key); // start with a fresh sorted set
for (int i = 0; i < 6; i++)
{
Console.WriteLine("Calculating {0}", companies[i]);
// simulate expensive computation
Thread.Sleep(5000);
// add company with respective score
database.SortedSetAdd(key, companies[i], companyScores[i]);
}
}
The problem with this approach is that anytime a client accesses this data structure while it’s still being built, they will get partial data:
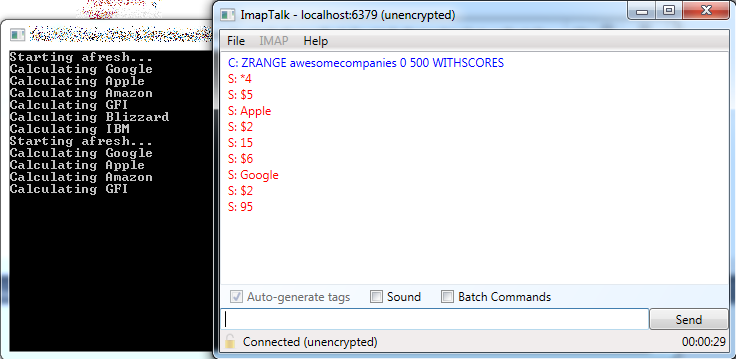
That sucks, because we want the data to be fresh, but we also want it to be complete when it is handed to clients.
Double Buffering in Computer Graphics
There is a technique in computer graphics called double buffering which solves a similar problem. Here’s some background from Wikipedia:
“In computer graphics, double buffering is a technique for drawing graphics that shows no (or less) flicker, tearing, and other artifacts.
“It is difficult for a program to draw a display so that pixels do not change more than once. For instance to update a page of text it is much easier to clear the entire page and then draw the letters than to somehow erase all the pixels that are not in both the old and new letters. However, this intermediate image is seen by the user as flickering. In addition computer monitors constantly redraw the visible video page (at around 60 times a second), so even a perfect update may be visible momentarily as a horizontal divider between the “new” image and the un-redrawn “old” image, known as tearing.
“A software implementation of double buffering has all drawing operations store their results in some region of system RAM; any such region is often called a “back buffer”. When all drawing operations are considered complete, the whole region (or only the changed portion) is copied into the video RAM (the “front buffer”); this copying is usually synchronized with the monitor’s raster beam in order to avoid tearing. Double buffering necessarily requires more memory and CPU time than single buffering because of the system memory allocated for the back buffer, the time for the copy operation, and the time waiting for synchronization.”
In short, double buffering involves the following steps:
- Draw the next frame (screen image) in a temporary location in memory that isn’t directly visible to the user (the back buffer)
- Swap the front buffer (the actual image on the screen) with the back buffer
That way, the change between the old image and the new one is instantaneous and the user will never notice the difference.
Double Buffering in Redis
We can apply a similar technique in Redis as follows:
- Build the new sorted set using a separate, temporary key
- Rename the temporary key to the existing key (implicitly deletes the temporary key)
This is how it works out in practice:
public static void PopulateAwesomeCompanies(IDatabase database)
{
var tempKey = "awesomecompaniestemp";
var key = "awesomecompanies";
Console.WriteLine("Starting afresh...");
for (int i = 0; i < 6; i++)
{
Console.WriteLine("Calculating {0}", companies[i]);
// simulate expensive computation
Thread.Sleep(5000);
// add company with respective score
database.SortedSetAdd(tempKey, companies[i], companyScores[i]);
}
// replace actual data in key with fresh data from tempKey
database.KeyRename(tempKey, key);
}
Here, we aren’t deleting any data structure before we begin, as we did before. Instead, we build our fresh sorted set using the temp key, and then copy it over to the actual key (the one that clients will be requesting). We do this using the Redis RENAME command, which copies the data from the temp key to the actual key, and implicitly also deletes the temp key. Since Redis is single-threaded, this operation is atomic and there is no race condition risk while the rename operation is happening.
The result of this is that the client will always have access to the latest complete data, even while the data structure is being rebuilt: