Kubuntu, the KDE flavour of Ubuntu, seems to work very well out of the box when installed on a new machine, needing very little configuration. One instance where you need to take that extra step is to allow taps on a laptop touchpad to be interpreted as clicks. For some reason I can’t imagine, this is not enabled by default.
Note: I’m using Kubuntu 20.04 LTS with KDE Plasma 5.18.5.
To enable this, you need to go into System Settings -> Input Devices -> Touchpad. You can reach the Touchpad settings directly by searching for “touchpad” in the search box (top-left in System Settings).
In Touchpad settings, enable “Tap-to-click”.
Once in the Touchpad settings, all you need to do is enable the “Tap-to-click” option. Once this is enabled, there are additional settings you can customise, but there’s typically no need to change them.
So you’ve set up Unity3D on Linux, but now you need a good text editor to write your scripts. In that case, you can consider using Visual Studio Code (VS Code for short), a cross-platform text editor from Microsoft. VS Code has become hugely popular for web development, but its versatility means that it can also be used for programming in languages such as C#, Python, Go, etc.
Note that I am using Linux Kubuntu 20.04 (LTS) and Unity3D 2020.3.15f2 (LTS).
Installing VS Code
The VS Code documentation explains how to set up VS Code on Linux. The easiest option is via the snap package manager as follows:
sudo snap install --classic code
Alternatively, you can download and install a .deb or .rpm package of you prefer. See the documentation for details.
Configuring the External Editor in Unity3D
Next, we’ll configure Unity3D to use VS Code as its external editor for scripts.
First, you’ll need to have the “Visual Studio Code Editor” package installed. This is set up for you when you create a new project, but you can double-check via the Window menu and then Package Manager:
Visual Studio Code Editor 1.2.3 is installed.
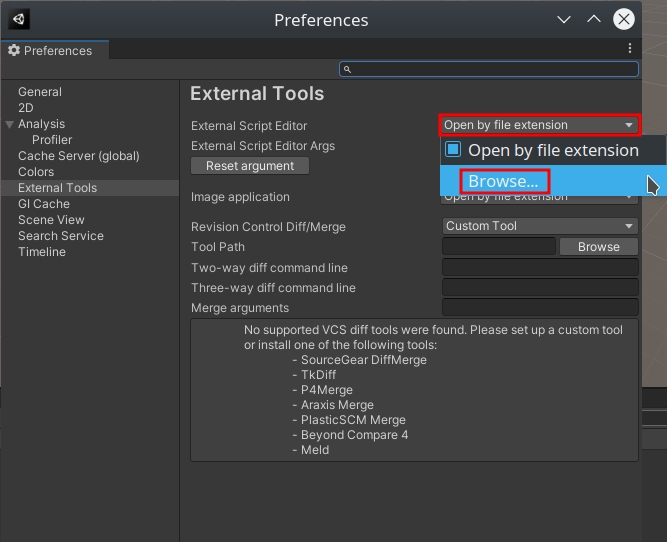
With that in place, go to the Edit menu and then Preferences… and switch to the External Tools tab. Click the dropdown next to the “External Script Editor” setting and then Browse… for the VS Code executable. If you don’t know where it is, use the following command in a terminal to locate it. In my case it’s at /snap/bin/code.
whereis code
To set VS Code as the Unity3D script editor, go to the Edit menu -> Preferences…, switch to the External Tools tab and then set the value of “External Script Editor” to the path to the VS Code executable.
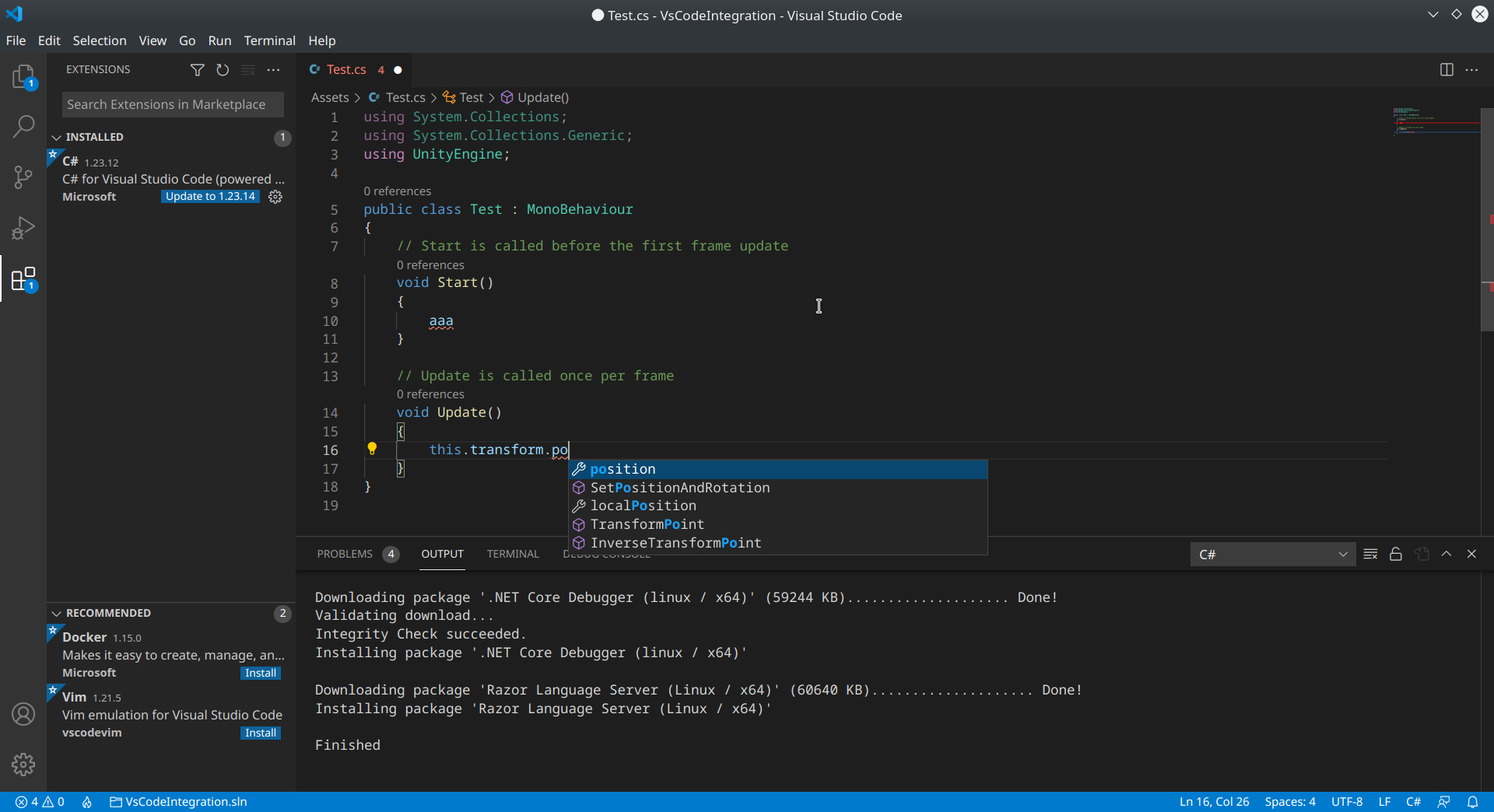
Now, if you create a C# script in Unity3D and open it, it should open in VS Code.
Configuring VS Code for Unity3D
You can now write C# scripts for Unity3D in VS Code and you have syntax highlighting to help you. However, Intellisense — the helpful suggestions that pop up e.g. when you try to access an object’s properties — doesn’t work yet. You also don’t get any indication of C# syntax errors. Let’s fix this so that we can write Unity3D scripts in a comfortable environment.
Update 14th May 2023: The rest of this section below is now obsolete. A breaking change was applied to OmniSharp last year that removed the omnisharp.useGlobalMono setting and changed the default value of the omnisharp.useModernNet setting to true. This way, you can install a recent version of the .NET Core SDK (e.g. 6.0) and configure it in the VS Code Omnisharp settings (Ctrl+Shift+P, search for “omnisharp sdk”, set path and version). It’s not necessary to install Mono.
Update 12th June 2023: After much fiddling around, I found that Intellisense only really works if you set useModernNet to false. OmniSharp seems to download a Mono version of its own, so I’m not sure whether a .NET Core SDK is necessary at all, without tinkering further.
Next, head to the Mono Download page, and follow the first set of instructions to add the Mono repository to your system. Then, for the second step, install mono-complete instead of mono-devel as shown below. (Note: don’t run the following command before first setting up the Mono repository. The version coming from the Ubuntu repositories doesn’t seem to play well with VS Code and Unity3D.)
sudo apt-get install mono-complete
Then, in VS Code, go to the Extensions tab on the left, search for “C#”, and install the first extension that comes up:
Install the C# extension for Visual Studio by Omnisharp.
Open up settings via File menu -> Preferences -> Settings (or Ctrl+, (control comma)) and search for “Omnisharp: Use Global Mono“, then set its value to “always”. Click “Restart Omnisharp” from the notification that appears at the bottom-right. You can also restart Omnisharp at any time by pressing Ctrl+Shift+P and selecting “OmniSharp: Restart OmniSharp”.
In Settings, set “Omnisharp: Use Global Mono” to “always” and then restart OmniSharp.
Still No Intellisense?
The above steps are usually enough to get Intellisense working, but as I’m writing this right now, it doesn’t seem to work. To fix this, I had to downgrade the C# extension in VS Code, as follows:
Go into the Extensions tab in VS Code.
Locate the C# extension by OmniSharp.
Click the small arrow next to the “Uninstall” button.
Select “Install Another Version…”
In my case, the latest version (1.23.14) was released just 3 days ago. I went for an older version that had been around for a couple of months (1.23.12).
Click the “Reload Required” button.
Watch the Output and wait for OmniSharp to finish downloading and installing.
Install Another VersionChoose versionReload RequiredInstalling C# dependencies
Testing Intellisense
VS Code should now provide Intellisense as you type, and you should also see syntax errors called out via both a squiggly red underline and in the Problems window below.
Intellisense and errors both work.
You should now be all set up. Happy game development!
Painkiller is a little-known gem in the first-person shooter (FPS) genre. I’ve played through it many times, but my most recent playthrough had something different: I did it entirely on Linux (Kubuntu 20.04 LTS).
All along, I’ve been using the Painkiller Black Edition from GOG.com, which has a Windows-only installer of close to 4GB that you can download after purchasing the game.
Downloading the Painkiller installer from GOG.com.
Once downloaded, we can install the game by opening a terminal, navigating to the directory where it downloaded, and running the installer with WINE, as I’ve shown many times before in previous articles (note that that’s a single filename… the spaces should actually be underscores):
cd Downloads
wine setup_painkiller_black_1.64_lang_update_\(24538\).exe
This brings up the GOG installer for Painkiller, so you select the installation language, tick the box accepting the EULA, and optionally choose the folder to install to.
The GOG installer for Painkiller.
Click the Install button to begin the installation, and the installer runs into a snag towards the end:
Runtime Error (at 73:1379)
Runtime Error (at 211:814) – Out of Global Vars range.
Same error a second time.
Invalid Opcode.
Errors come up when installing Painkiller.
This problem has happened to me with several GOG games before, and each time, I thought all was lost. So it was to my great surprise that, when I clicked the Launch button after closing the error, the game ran perfectly fine anyway.
I was able to play through the entire game without problems, so if you get this error while installing Painkiller (or another GOG game) with WINE, just ignore it and try playing anyway. Chances are it will be fine.
Playing the Game
Monster at the Cathedral
City on Water
The Palace
You can run Painkiller by double-clicking the handy desktop icon it sets up for you. At that point, all that’s left is to enjoy the action and stunning visuals.
The campaign selection screen in Warcraft III: The Frozen Throne
Over the past week, I’ve played through the Bonus (Orc) Campaign of the Warcraft III: The Frozen Throne expansion… on Linux! It’s both surprising and delightful how many games that could previously run only on Windows can nowadays be run on Linux with little trouble, especially since Windows 10 is no longer able to run some of those older games. In the case of Warcraft III, only the cinematics don’t seem to work on Linux (more on this further below).
In this article, I’ll show how to set up the original Warcraft III: Reign of Chaos and its expansion Warcraft III: The Frozen Throne on Linux, assuming you have the original CDs. I won’t be covering the recent remaster, Warcraft III: Reforged. I’m using Kubuntu 20.04 LTS.
We’ll be using WINE, so the steps are going to be pretty much the same as “Running Legacy Windows Programs on Linux with WINE“, although this will be tailored for Warcraft III. Make sure you already have WINE installed by running:
sudo apt-get install wine
Installing Warcraft III: Reign of Chaos
Start by popping in the Warcraft III: Reign of Chaos CD. When the Device Notifier shows the CD, expand the “Warcraft III” device and click “Open with File Manager” to mount the CD and open it in Dolphin, the file manager application in KDE. This may vary a little if you’re using a different desktop environment (e.g. GNOME).
Expand the “Warcraft III” device and click “Open with File Manager”.
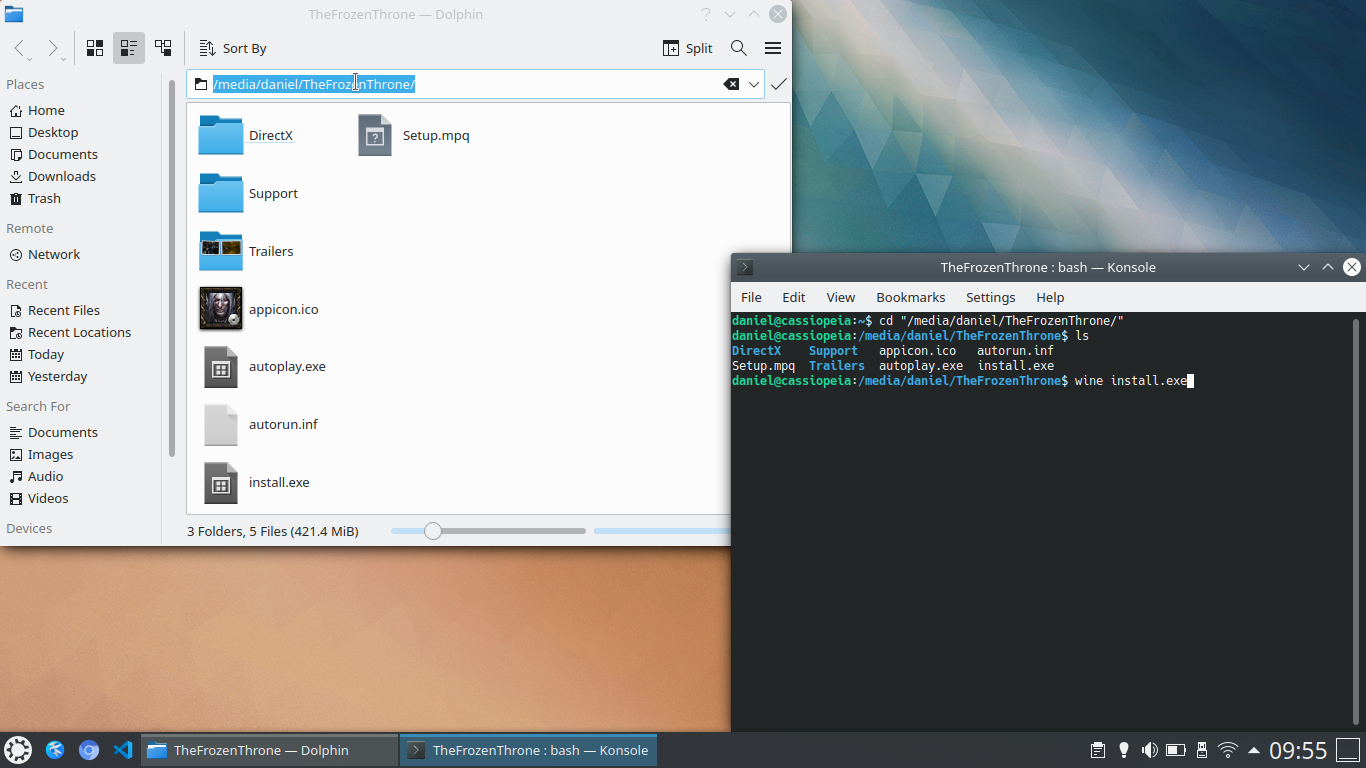
From the file manager application that opened, you can click the URL to find out the location where the CD has been mounted. Open a terminal and cd to that location. Then, run wine install.exe:
Click the URL in Dolphin to find the location where the CD has been mounted. cd to it in a terminal, then run wine install.exe.
This brings up the autorun screen. From here on, installing Warcraft III is just the same as on Windows.
The autorun screen
Accept the License Agreement to continue
Enter your name and CD Key
Choose where to install Warcraft III
Wait for Warcraft III to install
Create a desktop shortcut
Optionally, register Warcraft III
Warcraft III is ready to play
Running Warcraft III in Linux
Installing and playing Warcraft III: Reign of Chaos on Linux Kubuntu 20.04 LTS
When it asks you whether you want to create a desktop shortcut, click “Yes”. This creates a shortcut as well as an extra .lnk file, which you can delete. You can use this desktop shortcut, the one added to your start menu, or the autorun screen to run the game.
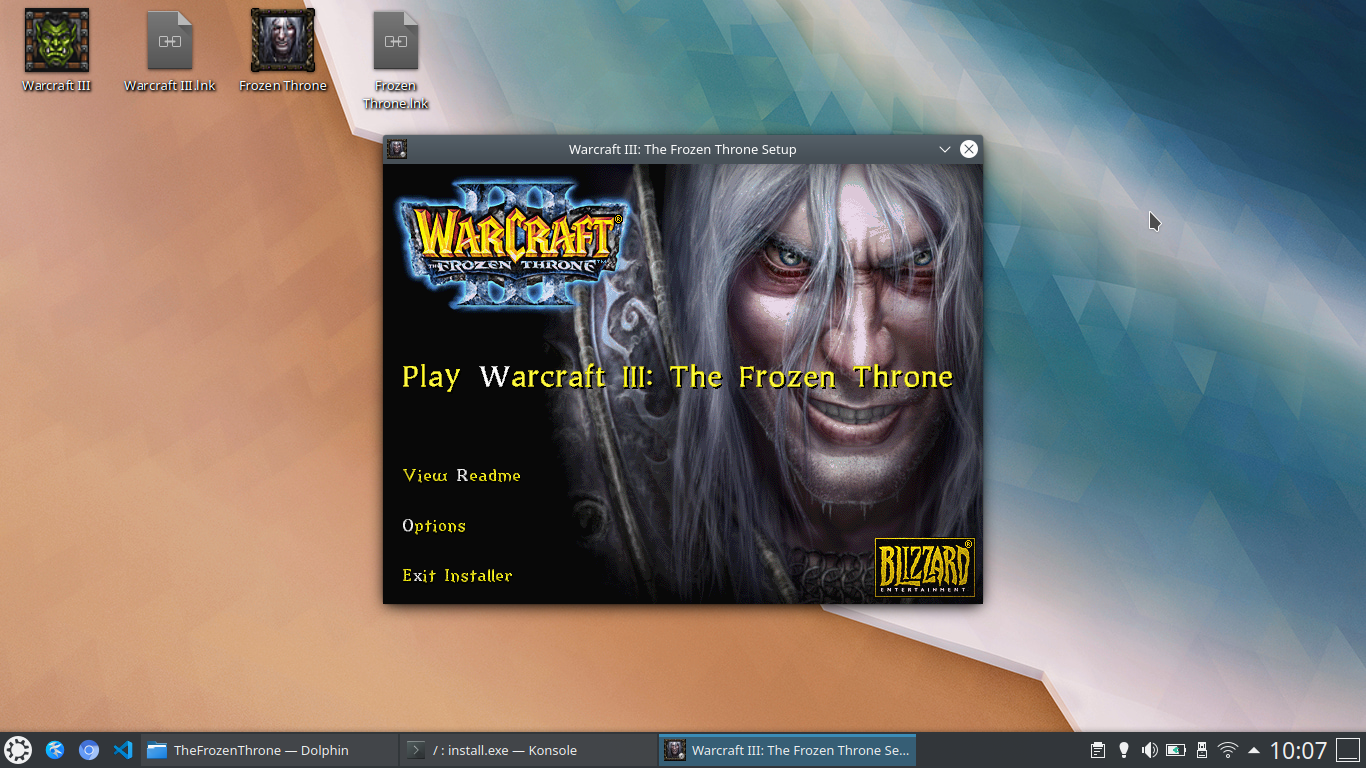
Installing Warcraft III: The Frozen Throne
Next, pop in the CD for Warcraft III’s The Frozen Throne expansion. Follow the same steps as with Reign of Chaos to bring up the autorun screen. From there, install the game the same way you would on Windows.
Note: if, for any reason, the mounted CD folder appears to be empty, simply eject the CD, put it back in the CD drive, and repeat the same steps.
Open The Frozen Throne with File Manager
Run the autorun using WINE
The autorun screen
Accept the License Agreement to continue
Enter your CD Key
Wait for it to install
Create a desktop shortcut
Optionally, register The Frozen Throne
The Frozen Throne is ready to play
Running The Frozen Throne in Linux
Installing and playing Warcraft III: The Frozen Throne on Linux Kubuntu 20.04 LTS
As with Warcraft III: Reign of Chaos, creating a desktop shortcut will create an extra .lnk file which you can delete.
Installing The Frozen Throne Patch 1.22a
The problem with playing Warcraft III: The Frozen Throne from CD is that… it’s not exactly complete. While you can play through the main campaigns, there’s also a Bonus Campaign based around the Orcs in their new home of Durotar. The CD features only Act One of this RPG/RTS hybrid campaign. To get the other two acts, you’ll have to patch it.
The two missing acts from the Bonus Campaign were added in patch 1.13, and patch 1.21b no longer requires the CD to play. There are also lots of gameplay changes from all the patches since the initial release.
To patch your game, first download The Frozen Throne Patch 1.22a – I’m not sure whether it’s still available on battle.net, but various third party websites should still be offering it for download; so just Google it. Then, run the patch executable with WINE:
wine War3TFT_122a_English.exe
The patch is quick to install, and when the game runs again, you should see an updated version at the bottom right of the initial screen.
After installing TFT patch 1.22a
TFT version is updated in bottom right
Installing The Frozen Throne patch 1.22a
What about Cinematics?
Unfortunately, I haven’t managed to get the beautiful cinematics to play from within Warcraft III. However, you can play them separately with a good media player such as VLC. To do this, first locate your Warcraft III installation folder via the hidden .wine folder in your home directory, as shown in the screenshot below. You’ll find the cinematics in the Movies folder.
The Movies folder, and the Human Campaign intro playing in VLC
If you have any sort of interest in game development, you’ve probably heard of Unity3D. And if you’ve used it before, you probably know that it has for a long time been restricted to Windows and Mac in terms of development platforms. That changed recently, when they added support for Linux. In this article, I’ll show you how I set up Unity3D on my Kubuntu 20.04 installation, and if the distribution you’re using is close enough, the same steps will likely work for you as well.
Update 14th May 2023: if you get an error saying the repository isn’t signed, check out this forum post for a solution.
Download the Unity Hub, then open it.
After Unity Hub has finished downloading, run it. It’s a cross-platform AppImage, so you can either double-click it or run it from the terminal.
You have no valid licence… you filthy peasant!
Register an account on the Unity3D website if you don’t have one already. Once Unity Hub loads, it immediately complains about not having a licence. If you click “Manage License”, it will ask you to login. You can click on the resulting “Login” link, or else click the top-right icon and then “Sign in”, to log into Unity3D from Unity Hub.
This is where you sign in.
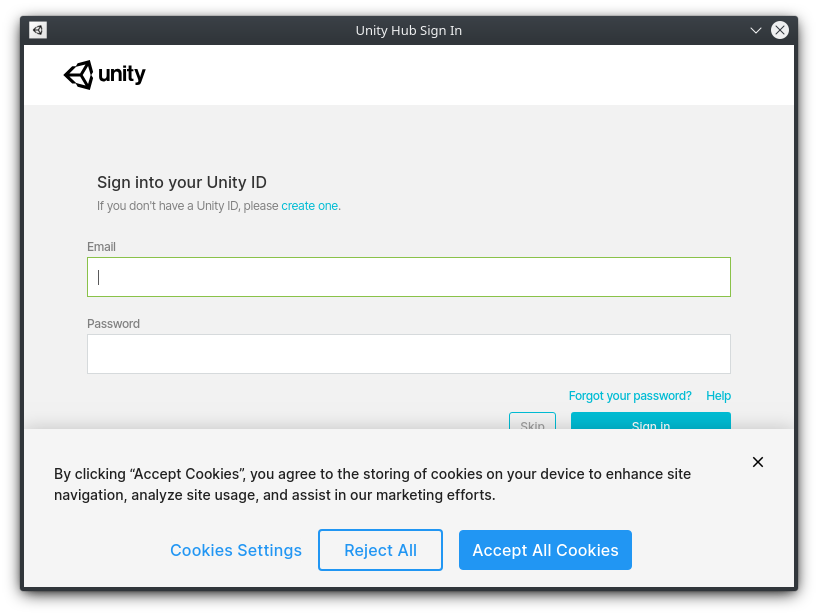
Reject cookies and login. Social providers are under the cookie banner.
Click “Reject All” to opt out of cookies. Then, sign in using your email address and password. Alternatively, if you log into your account using a social identity provider, you’ll find different providers’ icons under the cookie banner.
Now you’re back in the Licence page of Unity Hub. Wait a few seconds for it to activate, then click the “Activate New License” button:
After logging in, you can activate a new licence.
In the next window, select whichever options apply to you. If you’re just a hobbyist, Unity3D is free, so you can select the radio buttons as shown below. Click “Done” when you’re ready.
Choose the relevant options. Unity3D is free unless you’re a company making $100k or more.
You now have a licence! Click the arrow at the top-left to go to the Projects section.
Armed with a licence, go out of Preferences and back to the main sections.
If you try to add a new project, you’ll realise that you need to install a version of the Unity3D editor first. Head over to the Installs section to do this.
You can’t create a new project before you install a version of the Unity3D editor.
In the Installs section, click the “Add” button:
Add a version of the Unity3D editor from here.
Choose whichever version you prefer. The recommended LTS version is best if you need stability; otherwise you can use the latest and greatest version with the newest features.
Choose which version of the Unity3D editor you want to install. The recommended LTS is better for stability; if you’re just starting out, you don’t really need that and can go for the newest one instead.
Click “Next”, and you can now choose which platforms you want your builds to target and what documentation you want. If you’re just starting out, keep it simple and just leave the default “Linux Build Support” enabled. You can always add more stuff later if/when you need it.
Choose which platforms you want to target, and which documentation you want to include. If you’re just starting out, you don’t really care.
Click “Done”, and wait for it to install…
Grab some coffee.
When it’s done, head back to the Projects section. Click the “New” button to create a new project.
In the next window, select the type of project (3D by default), give it a name, and select a folder where your Unity3D projects will go (the new project will be created as a subfolder of this). Then click the “Create” button:
Choose project type, name and location.
Wait for it…
Nice loading screen…
And… that’s it! The editor then comes up, and you can begin creating your game.