RedisConf 2020 was originally planned to be held in San Francisco. The sudden spread of the COVID19 pandemic, however, meant that the organisers, like many others, had to take a step back and reconsider whether and how to run this event. In fact, the decision was taken in March for it to be held as a virtual event.
RedisConf 2020 will thus be an online conference taking place on the 12th and 13th of May 2020. The schedule is packed with talks, the first day being breakout sessions, and the second being full of training provided by the folks at Redis Labs.
Among the talks presented on the first day, you’ll find my own A Practical Introduction to RedisGraph, which introduces the relatively new RedisGraph graph database, and demonstrates what you can do with it via practical demonstration.
In “First Steps with RedisGraph“, after getting up and running, we used a couple of simple graphs to understand what we can do with Cypher and RedisGraph.
This time, we will look at a third and more complex example: building and querying a family tree.
The ancient Family Tree 2.0 application for Windows 95.
For me, this not just an interesting example, but a matter of personal interest and the reason why I am learning graph databases in the first place. In 2001, I came upon a Family Tree application from the Windows 95 era, and gradually built out my family tree. By the time I realised that it was getting harder to run with each new version of Windows, it was too big to easily and reliably migrate all the data to a new system. Fortunately, Linux is more capable of running this software than Windows.
This software, and others like it, allow you to do a number of things. The first and most obvious is data entry (manually or via an import function) in order to build the family tree. Other than that, they also allow you to query the structure of the family tree, bringing out visualisations (such as descendant trees, ancestor trees, chronological trees etc), statistics (e.g. average age at marriage, life expectancy, average number of children, etc), and answers to simple questions (e.g. who died in 1952?).
An Example Family Tree
In order to have something we can play with, we’ll use this family tree:
This is the example family tree that we will use throughout this article.
This data is entirely fictitious, and while it is a non-trivial structure, I would like to point out a priori several assumptions and design decisions that I have taken in order to keep the structure simple and avoid getting lost in the details of this already lengthy article:
All children are the result of a marriage. Obviously, this is not necessarily the case in real life.
All marriages are between a husband and a wife. This is also not necessarily the case in real life. Note that this does not exclude that a single person may be married multiple times.
When representing dates, we are focusing only on the year in order to avoid complicating things with date arithmetic. In reality, family tree software should not just cater for full dates, but also for dates where some part is unknown (e.g. 1896-01-??).
Parent-child relationships are represented as childOf arrows, from the child to each parent. This approach is quite different from others you might come across (such as those documented by Rik Van Bruggen). It allows us to maintain a simple structure while not duplicating any information (because the year of birth is stored with the child).
A man marries a woman. In reality, it should be a bidirectional relationship, but we cannot have that in RedisGraph without having two relationships in opposite directions. Having the relationship go in a single direction turns out to be enough for the queries we need, so there is no need to duplicate that information. The direction was chosen arbitrarily and if anyone feels offended, you are more than welcome to reverse it.
Loading Data in RedisGraph
As we’re now dealing with larger examples, it is not very practical to interactively type or paste the RedisGraph commands into redis-cli to insert the data we need. Instead, we can prepare a file containing the commands we want to execute, and then pipe it into redis-cli as follows:
There are certainly other ways in which the above commands could be rewritten to be more compact, but I wanted to focus more on keeping things readable in this case.
Sidenote: When creating the nodes (not the relationships), another option could be to keep only the JSON-like property structure in a file (see RedisGraph-FamilyTree/familytree-persons.txt), and then use awk to generate the beginning and end of each command:
Once the family tree data has been loaded, we can finally query it and get some meaningful information. You might want to keep the earlier family tree picture open in a separate window while you read on, to help you follow along.
Let’s get all of Anthony’s ancestors! Here we use the *1.. syntax to indicate that this is not a single relationship, but indeed a path that is made up of one or more hops.
How about Victoria’s descendants? This is the same as the ancestors query in terms of the MATCH clause, but it’s got the WHERE and RETURN parts swapped.
Can we get Donald’s ancestors and descentantsusing a single query? Yes! We can use the UNION operator to combine the ancestors and descentants queries. Note that in this case the AS keyword is required, because subqueries of a UNION must have the same column names.
GRAPH.QUERY FamilyTree "MATCH (c)-[:childOf*1..]->(p) WHERE c.name = 'Donald' RETURN p.name AS name UNION MATCH (c)-[:childOf*1..]->(p) WHERE p.name = 'Donald' RETURN c.name AS name"
1) 1) "name"
2) 1) 1) "Christina"
2) 1) "Joseph"
3) 1) "Victoria"
4) 1) "John"
5) 1) "George"
6) 1) "Anthony"
3) 1) "Query internal execution time: 78.088850 milliseconds"
Who are Donald’s cousins? This is a little more complicated because we need two paths that feed into the same parent, exactly two hops away (because one hop away would be siblings). We also need to exclude Donald and his siblings (if he had any) because they could otherwise match the specified pattern.
Update 4th December 2019: The ancestors and descendants query has been added, and the cousins query improved, thanks to the contributions of people in this GitHub issue. Thank you!
Statistical Queries
The last two queries I’d like to show are statistical in nature, and since they’re not easy to visualise directly, I’d like to get to them in steps.
First, let’s calculate life expectancy. In order to understand this, let’s first run a query retrieving the year of birth and death of those people who are already dead:
Since life expectancy is the average age at which people die, then for each of those born/died pairs, we need to subtract born from died to get the age at death for each person, and then average them out. We can do this using the AVG() aggregate function, which like COUNT() may be reminiscent of SQL.
The second statistic we’ll calculate is the average age at marriage. This is similar to life expectancy, except that in this case there are two people in each marriage, which complicates things slightly.
Once again, let’s visualise the situation first, by retrieving separately the ages of the female and the male when they got married:
Therefore, we have five marriages but ten ages at marriage, which is a little confusing to work out an average. However, we can still get to the number we want by adding up the ages for each couple, working out the average, and then dividing by 2 at the end to make up for the difference in the number of values:
We’ve seen another example graph — a family tree — in this article. We discussed the reasons behind the chosen representation, delved into efficient ways to quickly create it from a text file, and then ran a whole bunch of queries to answer different questions and analyse the data in the family tree.
One thing I’m still not sure how to do is whether it’s possible, given two people, to identify their relationship (e.g. cousin, sibling, parent, etc) based on the path between them.
As all this is something I’m still learning, I’m more than happy to receive feedback on how to do things better and perhaps other things you can do which I’m not even aware of.
RedisGraph is a super-fast graph database, and like others of its kind (such as Neo4j), it is useful to represent networks of entities and their relationships. Examples include social networks, family trees, and organisation charts.
Getting Started
The easiest way to try RedisGraph is using Docker. Use the following command, which is based on what the Quickstart recommends but instead uses the edge tag, which would have the latest features and fixes:
sudo docker run -p 6379:6379 -it --rm redislabs/redisgraph:edge
Redis with RedisGraph running in Docker
You will also need the redis-cli tool to run the example queries. On Ubuntu (or similar), you can get this by installing the redis-tools package.
Tom Loves Judy
We’ll start by representing something really simple: Tom Loves Judy.
When using redis-cli, queries will also follow the format of GRAPH.QUERY <key> "<cypher_query>". In RedisGraph, a graph is stored in a Redis key (in this case called “TomLovesJudy“) with the special type graphdata, thus this must always be specified in queries. The query itself is the part between double quotes, and uses a language called Cypher. Cypher is also used by Neo4j among other software, and RedisGraph implements a subset of it.
Cypher represents nodes and relationships using a sort of ASCII art. Nodes are represented by round brackets (parentheses), and relationships are represented by square brackets. The arrow indicates the direction of the relationship. RedisGraph at present does not support undirected relationships. When you run the above command, Redis should provide some output indicating what happened:
2 nodes and one relationship. Makes sense.
Since our graph has been created, we can start running queries against it. For this, we use the MATCH keyword:
GRAPH.QUERY TomLovesJudy "MATCH (x) RETURN x"
Since round brackets represent a node, here we’re saying that we want the query to match any node, which we’ll call x, and then return it. The output for this is quite verbose:
As you can see, this has given us the whole structure of each node. If we just want to get something specific, such as the name, then we can specify it in the RETURN clause:
It seems like Tom Loves Judy. Unfortunately, Judy does not love Tom back.
Company Shareholding
Let’s take a look at a slightly more interesting example.
Company A is owned by individuals X (85%) and Y (15%). Company B is owned by individuals Y (55%) and Z (45%).
In this graph, we have companies (blue nodes) which are owned by multiple individuals (red nodes). We can’t create this as a single command as we did before. We also can’t simply issue a series of CREATE commands, because we may end up creating multiple nodes with the same name.
Instead, let’s create all the nodes separately first:
You’ll notice here that the way we are defining nodes is a little different. A node follows the structure (alias:type {properties}). The alias is not much use in such CREATE commands, but on the other hand, the type now (unlike in the earlier example) gives us a way to distinguish between different kinds of nodes.
Now that we have the nodes, we can create the relationships:
GRAPH.QUERY Companies "MATCH (x:Individual { name : 'X' }), (c:Company { name : 'A' }) CREATE (x)-[:owns {percentage: 85}]->(c)"
GRAPH.QUERY Companies "MATCH (x:Individual { name : 'Y' }), (c:Company { name : 'A' }) CREATE (x)-[:owns {percentage: 15}]->(c)"
GRAPH.QUERY Companies "MATCH (x:Individual { name : 'Y' }), (c:Company { name : 'B' }) CREATE (x)-[:owns {percentage: 55}]->(c)"
GRAPH.QUERY Companies "MATCH (x:Individual { name : 'Z' }), (c:Company { name : 'B' }) CREATE (x)-[:owns {percentage: 45}]->(c)"
In order to make sure we apply the relationships to existing nodes (as opposed to creating new ones), we first find the nodes we want with a MATCH clause, and then CREATE the relationship between them. You’ll notice that our relationships now also have properties.
Now that our graph is set up, we can start querying it! Here are a few things we can do with it.
Last year I wrote an article about the right way to set up a Redis connection using StackExchange’s Redis client library. A lot of people found this useful, but at the same time the article went into a lot of detail in order to explain the dangers of doing this wrong. Also, there is a connection string format that’s a lot more concise.
So here’s how you set up a Redis connection using StackExchange.Redis, really quickly. If you need to just try this out quickly, you can grab a copy of Redis for Windows (just remember that this is not supported for production environments).
First, install the NuGet package for the Redis client library:
Install-Package StackExchange.Redis
Then, figure out what connection you need, and build a lazy factory for it (ideally the connection string should come from a configuration file):
My original article goes into detail on why this lazy construct is necessary, but it is mainly because it guarantees thread safety, so the ConnectionMultiplexer will be created only once when it is needed (which is how it’s intended to be used).
You build up a connection string using a comma-separated sequence of configuration parameters (as an alternative to ConfigurationOptions in code, which the original article used). This is more concise but also makes configuration a lot easier.
At the very least, you should have one or more endpoints that you’ll connect to (6379 is the default port in case you leave it out), abortConnect=false to automatically reconnect in case a disconnection occurs (see my original article for details on this), and a reasonable syncTimeout in case some of your Redis operations take long.
The default for syncTimeout is 1 second (i.e. 1000, because the value in milliseconds), and operations against Redis should typically be a lot less than that. But we don’t work in an ideal world, and since Redis is single-threaded, expensive application commands against Redis or even internal Redis operations can cause commands to at times exceed this threshold and result in a timeout. In such cases, you don’t want an operation to fail because of a one-off spike, so just give it a little extra (3 seconds should be reasonable). However, if you get lots of timeouts, you should review your code and look for bottlenecks or blocking operations.
Once you have the means to create a connection (as above), just get the lazy value, and from it get a handle on one of the 16 Redis databases (by default it’s database 0 if not specified):
var db = conn.Value.GetDatabase();
I’ve seen a lot of code in the past that just calls GetDatabase() all the time, for each operation. That’s fine, because the Basic Usage documentation states that:
“The object returned from GetDatabase is a cheap pass-thru object, and does not need to be stored.”
Despite this, I see no point in having an unnecessary extra level of indirection in my code, so I like to store this and work directly with it. Your mileage may vary.
Once you’ve got hold of your Redis database, you can perform your regular Redis operations on it.
Caching data is vital for high-performance web applications. However, cache retrieval code can get messy and hard to test without the proper abstractions. In this article, we’ll start an ugly multilevel cache and progressively refine it into something maintainable and testable.
A multilevel cache is just a collection of separate caches, listed in order of speed. We typically try to retrieve from the fastest cache first, and failing that, we try the second fastest; and so on.
For the example in this article we’ll use a simple two-level cache where:
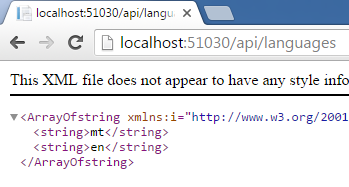
We’re going to build a Web API method that retrieves a list of supported languages. We’ll prepare this data in Redis (e.g. using the command SADD languages en mt) but will leave the MemoryCache empty (so it will have to fall back to the Redis cache).
A simple implementation looks something like this:
public class LanguagesController : ApiController
{
// GET api/languages
public async Task<IEnumerable<string>> GetAsync()
{
// retrieve from MemoryCache
var valueObj = MemoryCache.Default.Get("languages");
if (valueObj != null)
return valueObj as List<string>;
else
{
// retrieve from Redis
var conn = await ConnectionMultiplexer.ConnectAsync("localhost:6379");
var db = conn.GetDatabase(0);
var redisSet = await db.SetMembersAsync("languages");
if (redisSet == null)
return null;
else
return redisSet.Select(item => item.ToString()).ToList();
}
}
}
Data Access Repositories and Multilevel Cache Abstraction
The controller method in the previous section is having to deal with cache fallback logic as well as data access logic that isn’t really its job (see Single Responsibility Principle). This results in bloated controllers, especially if we add additional cache levels (e.g. fall back to database for third-level cache).
To alleviate this, the first thing we should do is move data access logic into repositories (this is called the Repository pattern). So for MemoryCache we do this:
public class MemoryCacheRepository : IMemoryCacheRepository
{
public Task<List<string>> GetLanguagesAsync()
{
var valueObj = MemoryCache.Default.Get("languages");
var value = valueObj as List<string>;
return Task.FromResult(value);
}
}
…and for Redis we have this instead:
public class RedisCacheRepository : IRedisCacheRepository
{
public async Task<List<string>> GetLanguagesAsync()
{
var conn = await ConnectionMultiplexer.ConnectAsync("localhost:6379");
var db = conn.GetDatabase(0);
var redisSet = await db.SetMembersAsync("languages");
if (redisSet == null)
return null;
else
return redisSet.Select(item => item.ToString()).ToList();
}
}
The repositories each implement their own interfaces, to prepare for dependency injection which is one of our end goals (we’ll get to that later):
public interface IMemoryCacheRepository
{
Task<List<string>> GetLanguagesAsync();
}
public interface IRedisCacheRepository
{
Task<List<string>> GetLanguagesAsync();
}
For this simple example, the interfaces look almost identical. If your caches are going to be identical then you can take this article further and simplify things even more. However, I’m not assuming that this is true in general; you might not want to have a multilevel cache everywhere.
Let’s also add a new class to abstract the fallback logic:
public class MultiLevelCache
{
public async Task<T> GetAsync<T>(params Task<T>[] tasks) where T : class
{
foreach(var task in tasks)
{
var retrievedValue = await task;
if (retrievedValue != null)
return retrievedValue;
}
return null;
}
}
Basically this allows us to pass in a number of tasks, each corresponding to a cache lookup. Whenever a cache lookup returns null, we know it’s a cache miss, which is why we need the where T : class restriction. In that case we try the next cache level, until we finally run out of options and just return null to the calling code.
This class is async-only to encourage asynchronous retrieval where possible. Synchronous retrieval can use Task.FromResult() (as the MemoryCache retrieval shown earlier does) to conform with this interface.
We can now refactor our controller method into something much simpler:
public async Task<IEnumerable<string>> GetAsync()
{
var memoryCacheRepository = new MemoryCacheRepository();
var redisCacheRepository = new RedisCacheRepository();
var cache = new MultiLevelCache();
var languages = await cache.GetAsync(
memoryCacheRepository.GetLanguagesAsync(),
redisCacheRepository.GetLanguagesAsync()
);
return languages;
}
The variable declarations will go away once we introduce dependency injection.
Multilevel Cache Repository
The code looks a lot neater now, but it is still not testable. We’re still technically calling cache retrieval logic from the controller. A cache depends on external resources (e.g. databases) and also potentially on time (if expiry is used), and that’s not good for unit tests.
A cache is not very different from the more tangible data sources (such as Redis or a database). With them it shares the function of retrieving data and the nature of relying on resources external to the application, which makes it incompatible with unit testing. A multilevel cache has the additional property that it is an abstraction for the underlying data sources, and is thus itself a good candidate for the repository pattern:
We can now move all our cache retrieval logic into a new MultiLevelCacheRepository class:
public class MultiLevelCacheRepository : IMultiLevelCacheRepository
{
public async Task<List<string>> GetLanguagesAsync()
{
var memoryCacheRepository = new MemoryCacheRepository();
var redisCacheRepository = new RedisCacheRepository();
var cache = new MultiLevelCache();
var languages = await cache.GetAsync(
memoryCacheRepository.GetLanguagesAsync(),
redisCacheRepository.GetLanguagesAsync()
);
return languages;
}
}
Our controller now needs only talk to this repository, and carry out any necessary logic after retrieval (in this case we don’t have any):
public async Task<IEnumerable<string>> GetAsync()
{
var repo = new MultiLevelCacheRepository();
var languages = await repo.GetLanguagesAsync();
return languages;
}
Dependency Injection
Our end goal is to be able to write unit tests for our controller methods. A prerequisite for that is to introduce dependency injection.
Note: you can also set up an interface for MultiLevelCache if you want. I didn’t do that out of pure laziness.
Next, refactor MultiLevelCacheRepository to get the classes it needs via constructor injection:
public class MultiLevelCacheRepository : IMultiLevelCacheRepository
{
private IMemoryCacheRepository memoryCacheRepository;
private IRedisCacheRepository redisCacheRepository;
private MultiLevelCache cache;
public MultiLevelCacheRepository(
IMemoryCacheRepository memoryCacheRepository,
IRedisCacheRepository redisCacheRepository,
MultiLevelCache cache)
{
this.memoryCacheRepository = memoryCacheRepository;
this.redisCacheRepository = redisCacheRepository;
this.cache = cache;
}
public async Task<List<string>> GetLanguagesAsync()
{
var languages = await cache.GetAsync(
memoryCacheRepository.GetLanguagesAsync(),
redisCacheRepository.GetLanguagesAsync()
);
return languages;
}
}
Do the same with the controller:
public class LanguagesController : ApiController
{
private IMultiLevelCacheRepository repo;
public LanguagesController(IMultiLevelCacheRepository repo)
{
this.repo = repo;
}
// GET api/languages
public async Task<IEnumerable<string>> GetAsync()
{
var languages = await repo.GetLanguagesAsync();
return languages;
}
}
…and make sure it actually works:
Unit Test
Thanks to this design, we can now write unit tests. There is not much to test for this simple example, but we can write a simple (!) test to verify that the languages are indeed retrieved and returned:
[TestMethod]
public async Task GetLanguagesAsync_LanguagesAvailable_Returned()
{
// arrange
var languagesList = new List<string>() { "mt", "en" };
var memCacheRepo = new Mock<MemoryCacheRepository>();
var redisRepo = new Mock<RedisCacheRepository>();
var cache = new MultiLevelCache();
var multiLevelCacheRepo = new MultiLevelCacheRepository(
memCacheRepo.Object, redisRepo.Object, cache);
var controller = new LanguagesController(multiLevelCacheRepo);
memCacheRepo.Setup(repo => repo.GetLanguagesAsync())
.ReturnsAsync(null);
redisRepo.Setup(repo => repo.GetLanguagesAsync())
.ReturnsAsync(languagesList);
// act
var languages = await controller.GetAsync();
var actualLanguages = new List<string>(languages);
// assert
CollectionAssert.AreEqual(languagesList, actualLanguages);
}
Over here we’re using Moq’s Mock objects to help us with setting up the unit test. In order for this to work, we need to make our GetLanguagesAsync() method virtual in the data repositories:
public virtual Task<List<string>> GetLanguagesAsync()
Conclusion
Caching makes unit testing tricky. However, in this article we have seen how we can treat a cache just like any other repository and hide its retrieval implementation details in order to keep our code testable. We have also seen an abstraction for a multilevel cache, which makes cache fallback straightforward. Where cache levels are identical in terms of data, this approach can probably be simplified even further.
"You don't learn to walk by following rules. You learn by doing, and by falling over." — Richard Branson