This article was originally posted here at Programmer’s Ranch on Saturday 16th November 2013. The syntax highlighting was added when the article was migrated here.
Hi everyone! 🙂
This article deals with how to solve the problem of building and setting an Entity Framework connection string at runtime, based on a database-first approach (i.e. you have generated an Entity Data Model based on an existing database). You are expected to be familiar with ADO .NET and the Entity Framework. The first part of the article deals with setting up an Entity Data Model and simple interactions with it; this should appeal to all readers. The second part deals with the custom connection string issue, and will be helpful only to those who have actually run into that problem.
We’re going to be using Visual Studio 2012, and Entity Framework 5.0. Start a new Console Application so that you can follow along.
Setting up the database
You can use whatever database you want, but in my case I’m using SQL Server Compact edition (SQLCE). If you’re using something else and already have a database, you can just skip over this section.
Unlike many of the more popular databases such as SQL Server and MySQL, SQLCE is not a server and stores its data in a file with .sdf extension. This file can be queried and updated using regular SQL, but is not designed to handle things like concurrent users – something which isn’t a problem in our case. Such file-based databases are called embedded databases.
If you have Visual Studio, then you most likely already have SQLCE installed. Look for it in “C:\Program Files (x86)\Microsoft SQL Server Compact Edition\v4.0“. Under the Desktop orPrivate folders you’ll find a file called System.Data.SqlServerCe.dll which we need to interact with SQLCE. Add a reference to it from your Console Application.
Now, we’re going to create the database and a simple one-table schema. We’ll use good old ADO.NET for that. We’ll create the database only if it doesn’t exist already. First, add the following usings at the top of Program.cs:
using System.IO; using System.Data.SqlServerCe;
In Main(), add the following:
String filename = "people.sdf"; String connStr = "Data Source=" + filename;
Since SQLCE works with just a file, we can create a basic connection string using just the name of the file we’re working with.
The following code actually creates the database and a single table called person.
try
{
// create database if it doesn't exist already
if (!File.Exists(filename))
{
// create the actual database file
using (SqlCeEngine engine = new SqlCeEngine(connStr))
{
engine.CreateDatabase();
}
// create the table schema
using (SqlCeConnection conn = new SqlCeConnection(connStr))
{
conn.Open();
String sql = @"create table person(
id int identity not null primary key,
name nvarchar(20),
surname nvarchar(30)
);";
using (SqlCeCommand command = new SqlCeCommand())
{
command.CommandText = sql;
command.Connection = conn;
int result = command.ExecuteNonQuery();
}
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
We first use SqlCeEngine to create the database file. Then we use ADO .NET to create the person table. Each row will have an auto-incrementing id (primary key), as well as a name and surname. Note that SQLCE does not support the varchar type, so we have to use nvarchar (Unicode) instead.
If you now build and run the application, you should find a people.sdf file in the bin\Debug folder. We’ll use that to create an Entity Data Model for the Entity Framework.
Creating the Data Model
Right click on the project and select Add -> New Item…:

From the Data category, select ADO.NET Entity Data Model. You can choose a name for it, or just leave it as the default Model1.edmx; it doesn’t really matter.

Click The Add button. This brings up the Entity Data Model Wizard.

The “Generate from database” option is the default selection, so just click Next.

Hit the New Connection… button to bring up the Connection Properties window.
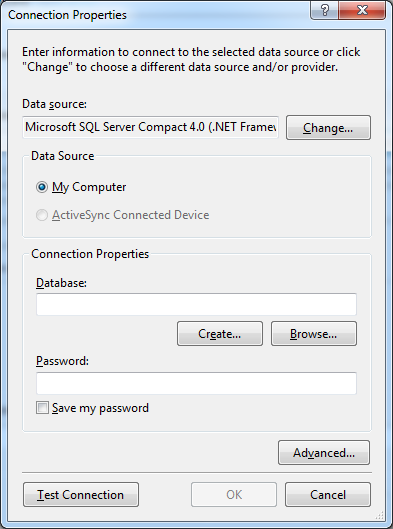
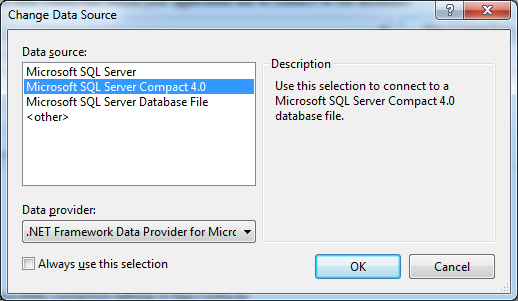
If SQL Server Compact 4.0 is not already selected as the Data source, click the Change… button and select it from the Change Data Source window:
Back in the Connection Properties window, click the Browse… button and locate the people.sdf file in your bin\Debug folder that we generated in the previous section. Leave the Password field empty, and click Test Connection. If all is well, you’ll get a message box saying that the test succeeded.
Once you click OK, the Entity Data Model Wizard should become populated with a connection string and a default name for the model:

When you click Next, you’ll get the following message:

Just click Yes and get on with it. In the next step, import the person table into your model by ticking the checkbox next to it:
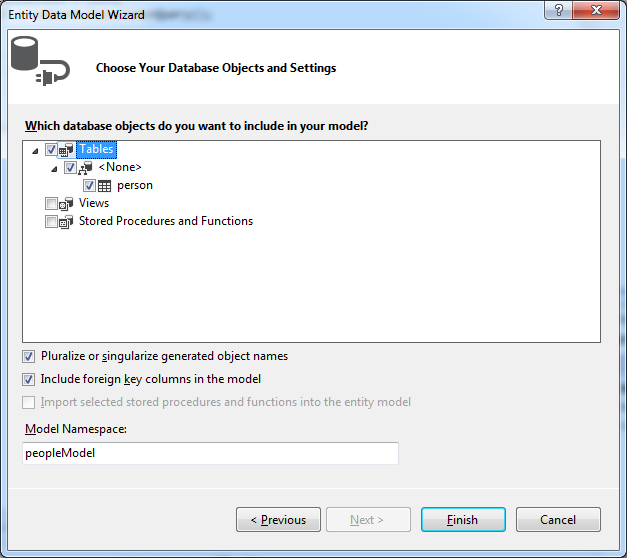
Click Finish. The files for your model are added to the project. You may also get the following warning:
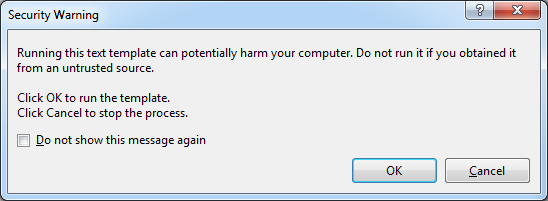
You don’t have to worry about it. Just click OK. If you click Cancel instead, you won’t have the necessary autogenerated code that you need for this project.
Interacting with the database using the Entity Framework
After the database-creation code from the first section, and before the end of the try scope, add the following code:
// interact with the database
using (peopleEntities db = new peopleEntities())
{
db.people.Add(new person() { name = "John", surname = "Smith" });
db.SaveChanges();
foreach (person p in db.people)
{
Console.WriteLine("{0} {1} {2}", p.id, p.name, p.surname);
}
}
Here, we create an instance of our entity context (peopleEntities) and then use it to interact with the database. We add a new row to the person table, and then commit the change via db.SaveChanges(). Finally, We retrieve all rows from the table and display them.
Also, add the following at the end of the Main() method so that we can see the output:
Console.ReadLine();
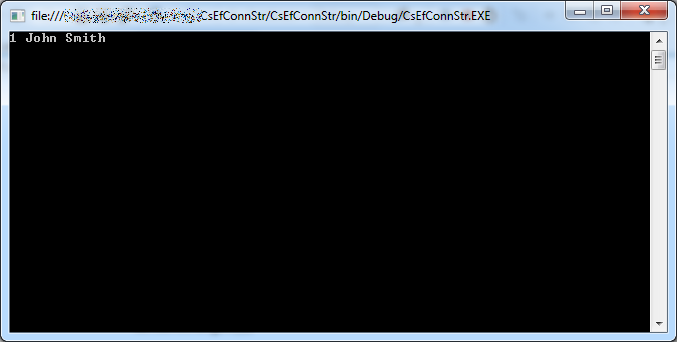
Run the program by pressing F5. The output shows that a row was indeed added:
The Entity Framework knows where to find the database because it has a connection string in the App.config file:
<connectionStrings>
<add name="peopleEntities" connectionString="metadata=res://*/Model1.csdl|res://*/Model1.ssdl|res://*/Model1.msl;provider=System.Data.SqlServerCe.4.0;provider connection string="data source=|DataDirectory|\people.sdf"" providerName="System.Data.EntityClient" />
</connectionStrings>
This might be good enough in some situations, but other times, we might want to build such connection string in code and ask the Entity Framework to work with it. A reason for this might be because the connection string contains a password, and you want to obtain it from an encrypted source. The following two sections illustrate how this is done.
Building a raw Entity Framework connection string
Let’s start out by commenting out the connection string in the App.config file:
<connectionStrings>
<!--
<add name="peopleEntities" connectionString="metadata=res://*/Model1.csdl|res://*/Model1.ssdl|res://*/Model1.msl;provider=System.Data.SqlServerCe.4.0;provider connection string="data source=|DataDirectory|\people.sdf"" providerName="System.Data.EntityClient" />
-->
</connectionStrings>
If you try running the program now, you’ll get a nice exception.
Now, what we want to do is add the connection string into our code and pass it to the entity context (the peopleEntities). So before our Entity Framework code (which starts with using (peopleEntities…), add the following:
String entityConnStr = @"metadata=res://*/Model1.csdl|res://*/Model1.ssdl|res://*/Model1.msl;provider=System.Data.SqlServerCe.4.0;provider connection string=&quot;data source=|DataDirectory|\people.sdf"";
If you now try to pass this connection string to the peopleEntities constructor, you’ll realise that you can’t. You can see why if you expand Model1.edmx and then Model1.Context.tt in Solution Explorer, and finally open the Model1.Context.cs file:

The peopleEntities class has only a parameterless constructor, and it calls the constructor of DbContext with the connection string name defined in App.config. The DbContext constructor may accept a connection string instead, but we have no way of passing it through peopleEntities directly.
While you could add another constructor to peopleEntities, it is never a good idea to modify autogenerated code. If you regenerate the model, any code you add would be lost. Fortunately, however, peopleEntities is a partial class, which means we can add implementation to it in a separate file (see this question and this other question on Stack Overflow).
Add a new class and name it peopleEntities. Add the following at the top:
using System.Data.Entity;
Implement the class as follows:
public partial class peopleEntities : DbContext
{
public peopleEntities(String connectionString)
: base(connectionString)
{
}
}
We can now modify our instantiation of peopleEntities to use our connection string as defined in code:
using (peopleEntities db = new peopleEntities(entityConnStr))
Since we are using a partial class defined in a separate file, any changes to the model will cause the autogenerated peopleEntities to be recreated, but will not touch the code we added in peopleEntities.cs.
When we run the program, we now get a very nice exception (though different from what we got right after commenting out the connection string in App.config):
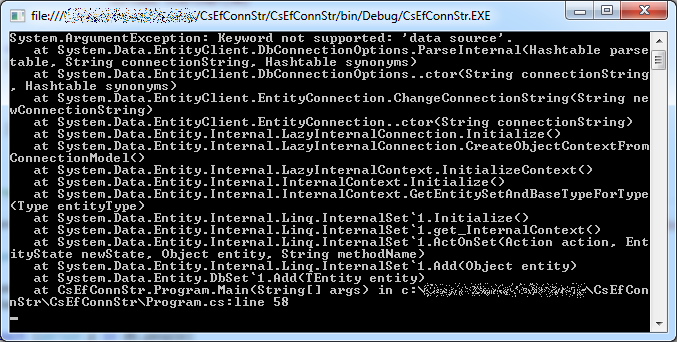
Apparently this happens because of the " values, which are necessary in XML files but cause problems when supplied in a String literal in code. We can replace them with single quotes instead, as follows:
String entityConnStr = @"metadata=res://*/Model1.csdl|res://*/Model1.ssdl|res://*/Model1.msl;provider=System.Data.SqlServerCe.4.0;provider connection string='data source=|DataDirectory|\people.sdf'";
If we run the program now, it works fine, and a new row is added and retrieved:
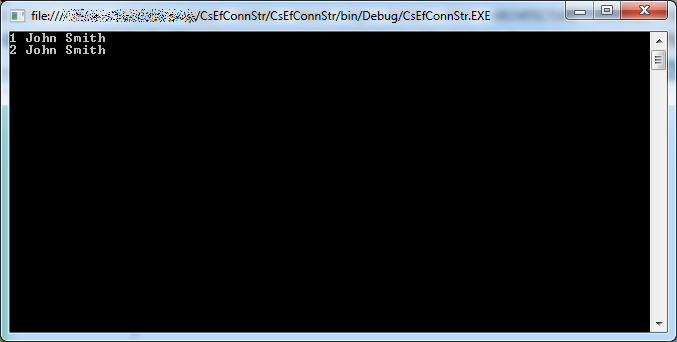
Using EntityConnectionStringBuilder
You’ll notice that the connection string we’ve been using is made up of three parts: metadata, provider, and the provider connection string that we normally use with ADO.NET.
We can use a class called EntityConnectionStringBuilder to provide these values separately and build a connection string. Using this approach avoids the problem with quotes illustrated at the end of the previous section.
First, remove or comment out the entityConnStr variable we have been using so far.
Then add the following near the top of Program.cs:
using System.Data.EntityClient;
Finally, add the following code instead of the connection string code we just removed:
EntityConnectionStringBuilder csb = new EntityConnectionStringBuilder(); csb.Metadata = "res://*/Model1.csdl|res://*/Model1.ssdl|res://*/Model1.msl"; csb.Provider = "System.Data.SqlServerCe.4.0"; csb.ProviderConnectionString = "data source=people.sdf"; String entityConnStr = csb.ToString();
When you run the program, it should work just as well:

Summary
This article covered quite a bit of ground:
- We first used the SqlceEngine and ADO .NET to create a SQL Server Compact database.
- We then created an Entity Data Model for this database.
- We added some code to add rows and retrieve data using the Entity Framework.
- We provided the Entity Framework with a raw connection string in code. To do this, we used a partial class to add a new constructor to the entity context class that can pass the connection string to the parent DbContext. We also observed a problem with using " in the connection string, and solved it by using single quotes instead.
- We used EntityConnectionStringBuilder to build a connection string from its constituent parts, and in doing so completely avoided the " problem.
I hope you found this useful. Feel free to leave any feedback in the comments below. Check back for more articles! 🙂