Visual Studio Code (VS Code) is a wonderful IDE. I’m not generally known to praise Microsoft’s products, but VS Code lets me develop and debug code productively in all the languages I’ve needed to work with, on any operating system. I don’t even use Visual Studio any more.
Launch configurations are at the heart of debugging with VS Code. In this article, I’ll explain how you can debug code using different languages, even at the same time. I’ll also show you how you can customise these launch configurations to pass command-line arguments, set environment variables, run pre-launch tasks, and more.
Getting Started with Launch Configurations
Anytime you want to debug something, you just press F5 (like in Visual Studio). Initially, you probably won’t have any launch configurations set up, in which case you’ll be prompted to choose what kind of launch configuration you want to create, as shown in the screenshot below. This list might vary depending on the language runtimes you have installed. When you select one, you’ll be guided towards creating a sample launch configuration.
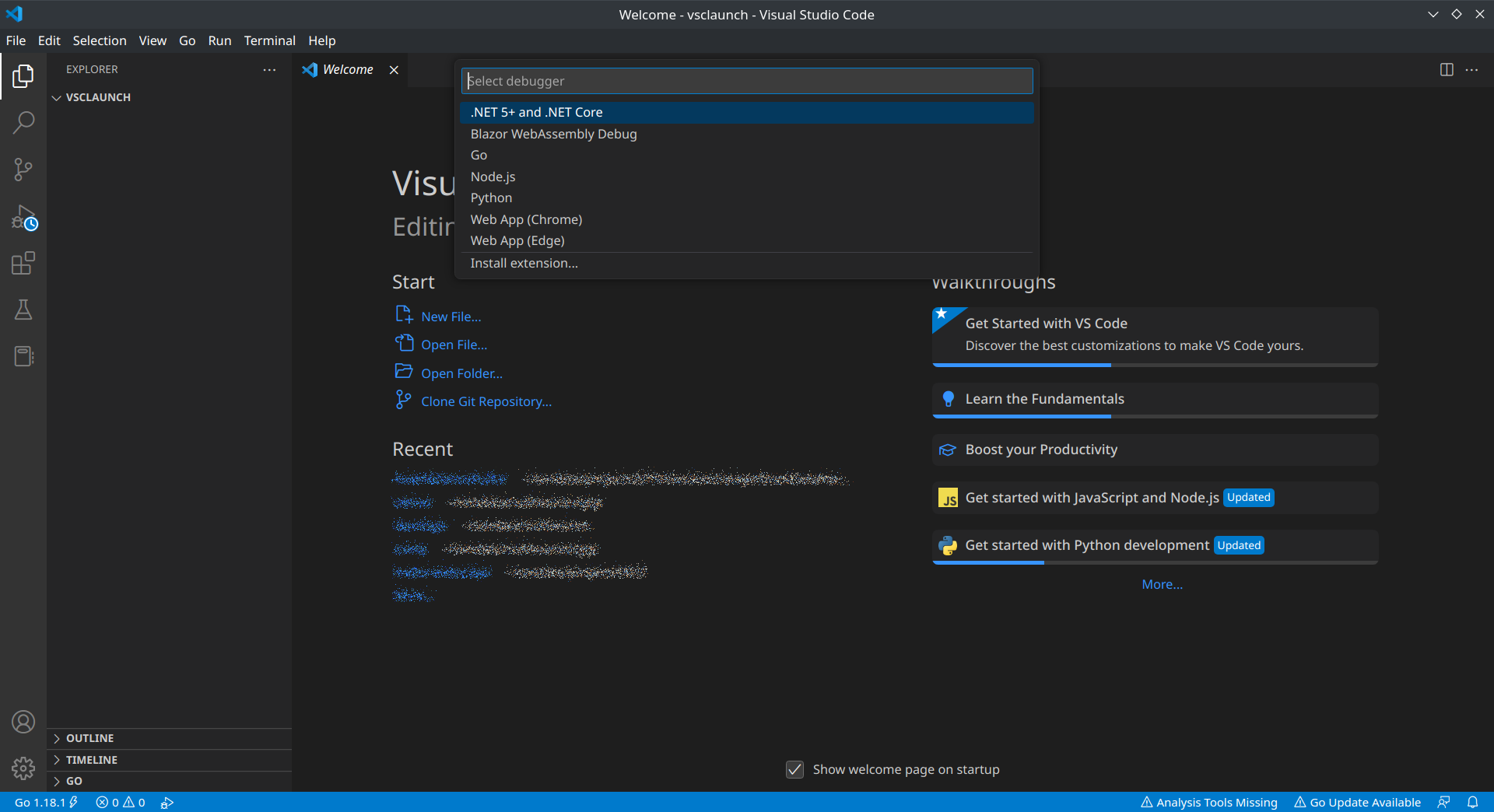
Another way is to click on the Debug tab on the left, which looks like a play button. You can then click the link to “create a launch.json” file, shown in the screenshot below. We’ll see this in practice in the next sections as we create launch configurations for various languages.

Debugging Python
Before we debug anything, we need some code. Let’s add a folder with a Python file in it, and add the following code:
import time
import datetime
while True:
time.sleep(1)
print(f"Swiss church bells say it's {datetime.datetime.now()}")
If I press F5, this actually works for me out of the box:

Clicking next to a line number adds a breakpoint. When the program hits that point, it pauses and allows us to inspect variables and other things. You can press F10 to go to the next statement, F11 to step into a function call, and Shift+F11 to step out. While a tutorial on how to debug code is outside the scope of this article, if you’re unfamiliar with debugging, this should at least be enough to get you started.

A Launch Configuration for Python
Follow either of the methods in the earlier “Getting Started” section to create your first Python launch configuration. This creates a launch.json file under a .vscode folder with the following contents. As launch.json may contain personally customised configurations for different developers (e.g. with different input parameters), it’s best not to commit it to source control.
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true
}
]
}
There isn’t much to it: this will simply run whatever file you have open in VS Code (which is what ${file} means). This is useful if you want to run specific files (I do this with tests in Go for instance), but not so much if you have a program with a single entry point and want to run that regardless of what you have open in VS Code. In that case, it’s easy to change the program value:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Main File",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/pyticker/main.py",
"console": "integratedTerminal",
"justMyCode": true
}
]
}
${workspaceFolder} represents the folder we have open in VS Code, so this makes sure we’re relative to that. ${workspaceFolder}, ${file} and other such variables are documented in VS Code’s Variables Reference.
Command Line Arguments
Let’s modify our Python program as follows:
import time
import datetime
import sys
while True:
time.sleep(int(sys.argv[2]))
print(f"{sys.argv[1]} church bells say it's {datetime.datetime.now()}")
The program now takes the nationality of the church bells as well as the sleep interval from command-line arguments. We’re not doing validation or error-handling for the sake of brevity. The following is an example of how to execute this successfully from a terminal:
$ python3 main.py Maltese 5
Maltese church bells say it's 2023-02-15 19:04:28.311805
Maltese church bells say it's 2023-02-15 19:04:33.315787
Maltese church bells say it's 2023-02-15 19:04:38.319811
To pass the same command-line arguments when debugging with VS Code, we add args to the launch configuration:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python: Main File",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/pyticker/main.py",
"console": "integratedTerminal",
"justMyCode": true,
"args": ["Maltese", "5"]
}
]
}
Multiple Launch Configurations
As you no doubt noticed, launch.json contains a JSON array of configurations. That means it’s very easy to add more of these configurations, for instance, when you need to provide different inputs:
{
"version": "0.2.0",
"configurations": [
{
"name": "Python Ticker (Maltese)",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/pyticker/main.py",
"console": "integratedTerminal",
"justMyCode": true,
"args": ["Maltese", "5"]
},
{
"name": "Python Ticker (Swiss)",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/pyticker/main.py",
"console": "integratedTerminal",
"justMyCode": true,
"args": ["Swiss", "1"]
}
]
}
From the Debug tab, you can then select the configuration you want to run from the drop-down before hitting F5 to debug with that configuration:

A Launch Configuration for Node.js
Let’s add a new folder as a sibling to our Python folder, and add the following code in a new app.js file, completely disregarding cleanup for the sake of brevity and YOLO:
const fs = require('fs');
setInterval(() => {
message = `Swiss church bells say it's ${new Date()}`;
console.log(message)
fs.appendFileSync('ding-dong.txt', message + '\n');
}, 1000);
We can set up a simple launch configuration to run this in launch.json:
...
"configurations": [
{
"name": "Node.js Ticker",
"program": "${workspaceFolder}/jsticker/app.js",
"request": "launch",
"type": "node"
},
...
It works, writing output every second both to standard output and a file:

The only problem is that the file was created top-level, and since we only specified a filename in the code (not a folder or path), then this must mean that Node.js is running with the top-level folder in VS Code as the current working directory. We can change that in the launch configuration using cwd:
...
"configurations": [
{
"name": "Node.js Ticker",
"program": "${workspaceFolder}/jsticker/app.js",
"request": "launch",
"cwd": "${workspaceFolder}/jsticker",
"type": "node"
},
...
When we run this again, the file is created under the jsticker folder.
Pre-Launch Tasks
Sometimes you want to run something before starting your program. For instance, in my work setup, I generate Swagger docs and perform other prerequisite tasks. But since we’re not doing anything that fancy, we’ll just delete the ding-dong.txt file every time we run the “Node.js Ticker” launch configuration.
To do this, we first need to add a tasks.json file inside the .vscode folder, next to launch.json, and add the following to it:
{
"version": "2.0.0",
"tasks": [
{
"label": "rmfile",
"command": "rm",
"args": ["ding-dong.txt"],
"options":{
"cwd": "${workspaceFolder}/jsticker"
}
}
]
}
This defines a task called rmfile that will run rm ding-dong.txt from the jsticker folder. We then refer to this task in the relevant launch configuration using preLaunchTask:
...
{
"name": "Node.js Ticker",
"program": "${workspaceFolder}/jsticker/app.js",
"request": "launch",
"cwd": "${workspaceFolder}/jsticker",
"preLaunchTask": "rmfile",
"type": "node"
},
...
A Launch Configuration for Go (GoLang)
For Go, we need to:
- Run
go work initfrom the top-level folder opened in VS Code - Create a new folder alongside pyticker and jsticker
- Run
go mod init mainin it - Add the following code to a new main.go file:
package main
import (
"fmt"
"time"
)
func main() {
for {
now := time.Now()
fmt.Printf("Swiss bells won't stop ringing! It's %s!\n", now)
time.Sleep(time.Second)
}
}
We can now add a launch configuration for this Go program:
...
{
"name": "Go Ticker",
"type": "go",
"request": "launch",
"mode": "debug",
"program": "${workspaceFolder}/goticker/main.go"
},
...
And we can have lots of fun running and debugging it, as a reminder that Swiss church bells need to tell you the time all the time. It’s not like they sell watches in Switzerland or anything.

Environment Variables
As we’ve seen with the Python example, however, other countries also have church bells. Instead of using command-line arguments to customise the output, we’ll instead pass environment variables. First, we need to modify the code a little:
package main
import (
"fmt"
"os"
"strconv"
"time"
)
func main() {
for {
country := os.Getenv("COUNTRY")
intervalSecsStr := os.Getenv("INTERVAL_SECS")
intervalSecs, _ := strconv.Atoi(intervalSecsStr)
now := time.Now()
fmt.Printf("%s bells won't stop ringing! It's %s!\n", country, now)
time.Sleep(time.Duration(intervalSecs) * time.Second)
}
}
Then we add the relevant environment variables as key-value pairs in an env block in the launch configuration:
...
{
"name": "Go Ticker",
"type": "go",
"request": "launch",
"mode": "debug",
"program": "${workspaceFolder}/goticker/main.go",
"env": {
"COUNTRY": "Maltese",
"INTERVAL_SECS": "3"
}
},
...
When you run it again, it makes all the difference:

Go Build Flags
Go has some specific build flags that can’t be passed as regular command-line parameters, such as build tags or the Data Race Detector. If you want to use these, you’ll have to pass them via buildFlags instead:
...
"buildFlags": "-race",
...
Running Multiple Programs with Compounds
It’s common to need to run multiple programs at once, especially in a microservices architecture, or if there are separate backend and frontend applications. This can be done in VS Code using compound launch configurations. For instance, if we wanted to run both the Python and Go programs, we could define a compound as follows (compounds go after configurations in launch.json):
{
"version": "0.2.0",
"configurations": [
{
"name": "Go Ticker",
"type": "go",
"request": "launch",
"mode": "debug",
"program": "${workspaceFolder}/goticker/main.go",
"env": {
"COUNTRY": "Maltese",
"INTERVAL_SECS": "3"
}
},
{
"name": "Node.js Ticker",
"program": "${workspaceFolder}/jsticker/app.js",
"request": "launch",
"cwd": "${workspaceFolder}/jsticker",
"preLaunchTask": "rmfile",
"type": "node"
},
{
"name": "Python Ticker (Maltese)",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/pyticker/main.py",
"console": "integratedTerminal",
"justMyCode": true,
"args": ["Maltese", "5"]
},
{
"name": "Python Ticker (Swiss)",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/pyticker/main.py",
"console": "integratedTerminal",
"justMyCode": true,
"args": ["Swiss", "1"]
}
],
"compounds": [
{
"name": "Go and Python Tickers",
"configurations": ["Go Ticker", "Python Ticker (Swiss)"]
}
]
}
The compound simply refers to the individual launch configurations by name, and has a name of its own. It can then be selected from the drop-down in the Debug tab just like any other launch configuration. By running a compound, you can debug and hit breakpoints in any application that is part of that compound.
In fact, you’ll notice there is a new drop-down next to the debugging buttons towards the central-top part of the screen. This allows you to switch certain views (e.g. the Debug Console) between running applications.

Conclusion
We’ve seen that Launch Configurations allow you to run and debug applications in VS Code with great flexibility, including:
- Run the current file or a specific one
- Set the current working directory
- Run different programs
- Use different programming languages
- Set up different configurations even for the same program
- Pass command-line arguments
- Set environment variables
- Run/debug multiple programs at the same time
This provides a great IDE experience even for more complex application architectures in a monorepo.