Those Kibana users who prefer their software with a dark theme will be thrilled to know that Kibana actually does have a dark mode since version 7.0.0.
It can be enabled by following the steps illustrated below.
Go to Management from the left navigation.
Select Advanced Settings on the left.
Find the Dark mode setting somewhere further down in the page.
Switch on the Dark mode setting, then reload the page.
Like the sky on a stormy day, the page goes dark.
In fact, everything from Discover to Maps (and beyond) becomes dark.
Dark mode is a welcome feature for those who prefer darker tones on their screen as a matter of personal taste or to reduce eye strain.
On Thursday 25th April 2019, just two days ago, the Elastic team held the Elastic Stack 7.0 Live (Virtual) Event, in which they explained and showcased several of the features in the latest version of Elasticsearch and its accompanying tools that were released on 10th April.
A recording is available at the link above, and I highly recommend watching it. However, I am writing this summary for the sake of those who might want to quickly check out the highlights without spending close to two hours watching the recording, or for those who want to quickly locate some of the relevant information (video isn’t a great medium to search for info).
Overview
“This version of the Elastic Stack looks very different from our early releases. It’s […] a much more mature product. We’ve had… 7 years now to learn and grow. But really we’re still focusing on the same 3 principles that have made Elastic popular from the beginning: speed, scale and relevance.”
— Clint Gormley, Stack Team Lead
The Elastic team has invested a lot of work into making Elasticsearch easy to scale, in such a way that it works the same on a laptop and in a data centre with hundreds of nodes with minimal configuration. However, the harsh realities of distributed systems (disk corruptions, split brains, shard inconsistencies etc) make this a very hard problem to solve, and the team has over the years added incremental changes to improve the product’s resiliency.
It is this work that has led to cross-cluster replication (released in 6.5), the removal of the minimum master nodes setting (released in 7.0), and will also enable following a stream of changes as they happen in an index.
“Version 7 is the safest, most flexible, easiest to use and scalable version of Elasticsearch that we’ve ever delivered.”
— Clint Gormley, Stack Team Lead
Fundamental changes have also been made in the way search itself works. Elasticsearch 7.0 uses an algorithm called Block Max WAND to greatly improve the speed of queries at the cost of not knowing exactly how many documents matched. This is usually a reasonable tradeoff because people usually want to get the top N results, rather than knowing the total hit count.
The raw speedup given by this new algorithm also has implications in terms of relevance of results and usability. Because search is so fast, it is no longer costly to search for stop words, and thus precision and recall can be improved by including them. Work is also ongoing on a search-as-you-type feature that would not be possible without this new level of performance.
Using BKD-trees instead of inverted indices have also resulted in significant speedups, especially in the realm of geo-shapes where accuracy has also improved considerably as a result.
Kibana got a new design, as its role has grown from being used to visualise Elasticsearch data to becoming an all-encompassing tool to manage the Elastic stack.
Also new on the ingest side is something called the Elastic Common Schema, which is a consistent way to map similar data from different data sources (e.g. Apache, IIS, NGINX) into a single structure.
Kibana 7 Design Considerations
A demo of Kibana 7, both in a browser and a mobile simulator.
Kibana 7 sports a new design as a result of a design-at-scale problem. The number of services offered by Kibana (see the tab drawer to the left) has increased considerably, and this called for a consistent and usable layout that could cater for applications as diverse as maps and logging.
Kibana’s dark mode, making the logging UI look like a terminal.
Some of the more superficial (but by no means trivial) work that went into Kibana was related to making it responsive (i.e. it responds nicely when you resize the browser window) and mobile-friendly (which in the words of Dave Snider, Director of Product design, is still “pretty beta”), as well as the dark mode that applies a darker theme throughout the product.
More importantly, however, Kibana 7 wants users to focus on the content (search results, graphs, visualisations etc) rather than the Kibana tooling itself, and that means moving things like the date picker and even Kibana’s own navigation out of the way.
The new design is based on a set of values:
Accessible to everyone (colour-blindness, screen reader support, tab around without using a mouse, etc)
Themable (easy to change colours)
Responsive (works in different screen sizes)
Playful (make it feel like fun – lively animations and such)
Well-documented (important for a distributed and open-source company)
This design was achieved by building the Elastic UI Framework, a React and CSS library of all UI controls used to build Kibana. It is open-source and fully documented with demos.
Making Search Faster (and Easier)
An example from the demo showing a stop word query from two fields returned in 27ms, but did not return an accurate hit count.
The Block Max WAND algorithm makes search significantly faster when we don’t need the total hit count. A demo showing a query involving stop words showed that the search took more than 10 times as long without this optimisation as it did with it.
The same search, run with track_total_hits set to true. This gives an accurate total hit count, but the query is significantly slower.
The Block Max WAND optimisation, enabled by default in Elasticsearch 7.0, can be disabled at any time using the track_total_hits setting if an exact hit count is required. It is also disabled automatically when using aggregations, to which the optimisation cannot be applied. Even with the optimisation enabled, total hits are tracked up to a maximum of 10,000. You can tell whether the hit count is accurate or not by seeing whether the hits.total.relation value is “eq” (which means it’s accurate) or “gte” (which means the actual hit count will be greater than or equal to 10,000).
This ground-breaking enhancement to the way search works is beneficial not only in speeding up queries, but also in enabling new features. In fact, a search-as-you-type feature is under development and is planned for the 7.1 release. Aside from that, feature fields and interval queries are also mentioned in the presentation.
Cluster Resiliency and Scale
The role of the Cluster Coordination Subsystem.
Elasticsearch 7 brings with it a new cluster coordination subsystem, which is responsible for the ongoing healthy operation of an Elasticsearch cluster. This has led to the removal of the minimum_master_nodes setting, which could prove very painful pre-7.0. Master elections are also a lot faster (going from at least 3 seconds in pre-7.0 to a few hundred milliseconds in 7.0), and logging is available when things go wrong.
The new cluster coordination system has been verified using formal methods, typically employed in mission-critical systems. Also, upgrading to this new system can be done without downtime.
An important resiliency enhancement in 7.0 is the real-memory circuit breaker. Elasticsearch uses several circuit breakers, designed to push back on requests when under load to avoid out-of-memory errors. The new real-memory circuit breaker allows Elasticsearch to know exactly how much memory will be allocated, making it less likely to break while at the same time using less overhead.
Cross-cluster replication (which shares an acronym with Creedence Clearwater Revival) is production-ready in 7.0, and addresses a number of very real use cases.
Elasticsearch 7.0 also introduces production-ready cross-cluster replication, allowing changes to indices to be synchronised with remote Elasticsearch clusters. The slide shown above describes some use cases where this is useful.
Geo Gorgeous (i.e. Maps)
The support for geographical applications by Elasticsearch and Kibana has received a considerable boost in version 7. At a basic level:
geo_points and geo_shapes now fully use BKD-trees
Ingest nodes can now use the GeoIP processor, and Logstash has a geoip filter plugin
Kibana gets a Coordinate Map, Region Map, as well as Vega and Maps capabilities
A new geo_shape type makes geo_shape fields a lot easier to work with
Using BKD-trees for Geo Shapes yields incredible improvements.
The use of BKD-trees for Geo Shapes significantly reduces the complexity of their representation, and therefore their storage. This results in considerable speed (indexing and querying), space and accuracy improvements, as shown in the slide above (and further in the video).
Elasticsearch 7.0 also introduces the geo_tile aggregation, which (unlike the geo hashes in use so far) conforms to the Web Mercator specification. Grid tiles are thus actually square, and preserve identical aspect ratio at all scales and latitudes.
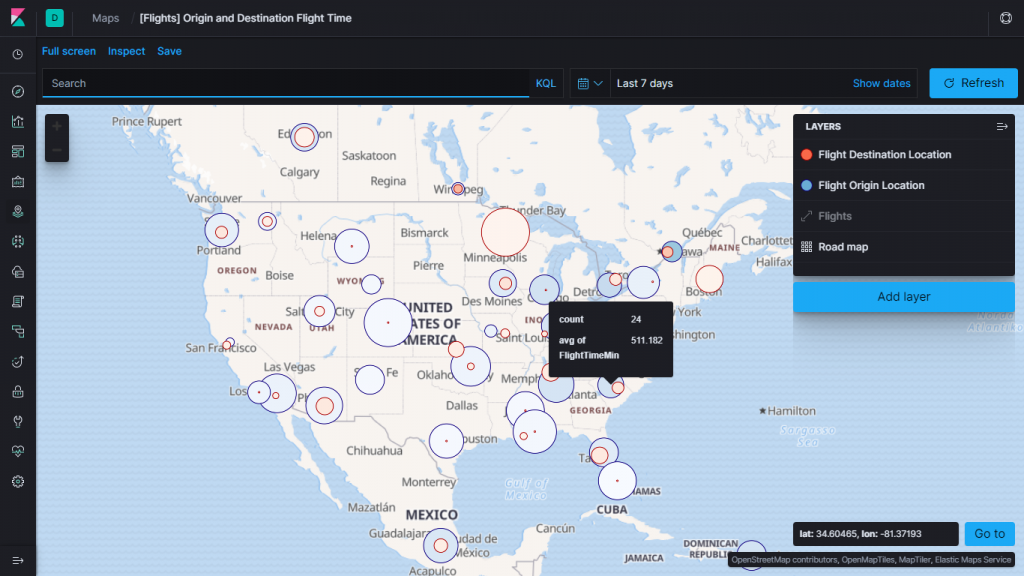
The rest of the presentation on geo focuses on Kibana Maps, which is beta in 7.0. It is a great tool allowing compisition of maps from multiple data sources, as the demo shows. The rest of the screenshots below are stills from the demo, and each demonstrates a particular functionality.
The demo is based on data that simulates network requests. A layer is added to the map based on the geographical location of each record, first as points, then as grid rectangles, and finally as a heat map.Another layer is added, bringing in countries from the Elastic Maps Service.Joining the point and country data results in country polygons shaded by the number of requests that originated there.It is possible to use a custom map service, as shown by this dark map coming from a third party source.Data centres (the big green circles) are added to the map.The location of individual requests (smaller green circles) are also added to the map, and gradually made smaller until they are barely visible.Request paths — lines connecting individual requests to data centres — are added as well.Since this is Kibana, the power of search is always available. The results are restricted to the last five minutes and to one particular data centre.
Summary (of the Summary)
Elastic Stack 7.0 is packed with new features and improvements. The launch event, still available on video and summarised in this article, barely scratches the surface. There is certainly a lot to be excited about.
Some items we’ve touched upon include:
Kibana has grown and got a redesign.
Block Max WAND significantly speeds up search (at the cost of total hit count), and paves the way for future features such as search-as-you-type.
A new cluster coordination subsystem, real-memory circuit breaker, and cross-cluster replication improve cluster resiliency and scale.
Significant improvements have been made in the geo space, and Kibana Maps is awesome.
Umbraco is a Content Management System (CMS) built on legacy ASP .NET (i.e. not .NET Core, and therefore Windows-only). A couple of months ago, version 8 was released, with breaking changes and some new features. In this article, we’ll see how to quickly get up and running with Umbraco 8.0.1 and Visual Studio Code.
Downloading Umbraco
The first thing to do is grab the Umbraco starter kit from the download page. At the time of writing this article, the latest version is 8.0.1.
The download link and installation guide link are shown in this screenshot.
Beneath the download link, there’s another link to the installation guide, which are mainly the steps we’ll be following in this article (despite the warning that it may not be updated for v8). Unfortunately, the “getting started” link further below (not shown in the screenshot above) is broken.
After downloading the Umbraco zip file, extract it to a folder of your choice.
Running Umbraco with Visual Studio Code
Visual Studio Code is a recent (compared to Visual Studio) cross-platform Integrated Development Environment (IDE) developed by Microsoft, and can often be used as a replacement for Visual Studio. Download Visual Studio Code if you don’t have it already.
Use the menu or the start page to “Open Folder…” and locate the directory where you extracted Umbraco.
After running Visual Studio Code, use its “Open folder…” option (via the start page or the file menu) to locate the folder where you extracted Umbraco to.
To install the IIS Express extension for Visual Studio: first, access the Extensions tab via the box-like icon on the left. Then, search for IIS Express, and select the relevant result when it comes up. Finally, hit the Install button.
Then, install the IIS Express extension for Visual Studio Code by following the steps illustrated in the above screenshot.
With that done, hit Ctrl+F5 to run the website. Be patient, as it may take a little while to load the first time.
PageInspector.Loader Assembly Issue
“Could not load file or assembly ‘Microsoft.VisualStudio.Web.PageInspector.Loader, Version=1.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a’ or one of its dependencies. The system cannot find the file specified.“
If you also have Visual Studio 2019 installed, then you might run into a problem that displays the above error instead of the website.
If this happens, locate the C:\ProgramData\Microsoft\VisualStudio\Packages\Microsoft.VisualStudio.AspNetDiagnosticPack.Msi,version=16.0.12311.10635 directory, run AspNetDiagnosticPack.msi, and hit Repair. After running the website again, it should work.
Installing Umbraco 8
After a little wait, the site should load and you should see the setup wizard:
The first page of the Umbraco setup wizard.
In the first screen (shown above), you give it your name, email address and a password. Then, you can choose whether to hit Install (which installs Umbraco with default settings, including an SQL Server Compact Edition (SQLCE) database), or else Customize and choose the options you want for the setup.
The installation itself will also take a while, but when that’s done, you’ll be redirected to the Umbraco CMS (which you can reach at any time via the /umbraco URL).
The login screen of the Umbraco CMS.
You can log in using the credentials that you supplied during the setup.
A first peek at the Umbraco 8 CMS: menu, navigation, content, and a tour.
Inside the CMS itself, you’ll get a quick tour of how the page layout is organised. If you’ve used Umbraco 7 or prior, you’ll notice that some things have been reorganised – for instance, the Developer section has been merged with the Settings section.
The Umbraco sample site that comes with the CMS download.
At this point, you can go ahead and start creating content. As you do this, you’ll see your changes reflected in the Umbraco Sample Site, which you can access by going to the root (/) of the website URL.
In this article, we’ll go through all the steps necessary to set up a basic Windows virtual machine (VM) in Amazon Web Services (AWS).
In AWS, the service used to manage VMs is called Elastic Compute Cloud (EC2). Thus, the first thing we need to do is access the EC2 service from the AWS Console homepage:
This brings us to the EC2 dashboard. We can click Instances in the left menu to get to the page where we can manage our VMs (note that we can also launch a VM / EC2 Instance directly from here):
The Instances page lists any VMs that we already manage, and allows us to launch new ones. Click on one of the Launch Instance buttons to create a new VM:
The next step is to select something called the Amazon Machine Image (AMI). This basically means what operating software and software you want to have on the VM. In our case, we’ll just go for the latest Windows image available:
The next thing to choose is the instance type. Virtual machines on AWS come in many shapes and sizes – some are general-purpose, whereas others are optimised for CPU, memory, or other resources. In our case we don’t really care, so we’ll just go for the general-purpose t2.micro, which is also free tier eligible:
Since we’re just getting started and don’t want to get lost in the details of complex configuration, we’ll just Review and Launch. This brings us to the review page where we can see what we are about to create, and we can subsequently launch it:
One thing to note in this page is that the instance launch wizard will create, aside from the EC2 instance (VM) itself, a security group. Let’s take note of this for now – we’ll get back to it in a minute. Hit the Launch button.
Before the VM is spun up, you are prompted to create or specify a key pair:
A key pair is needed in order to gain access to the VM once it is launched. You can use an existing key pair if you have one already; otherwise, select “Create a new key pair” from the drop-down list. Specify a name for the key pair, and download it. This gives you a .pem file which you will need soon, and also allows you to finally launch the instance.
Once you hit the Launch Instances button, the VM starts to spin up. It may take a few minutes before it is available.
Scroll down and use the View Instances button at the bottom right to go back to the EC2 Instances page. There, you can see the new VM that should be in a running state. By selecting the VM, you can see its Public DNS name, which you can use to remote into the VM (though we’ll see an easier way to do this in a minute):
Before we can remote into the machine, it needs to have its RDP port open. We can go to the Security Groups page to see the security group for the VM we created – remember that the instance launch wizard created a security group for us:
As you can see, the VM’s security group is already configured to allow RDP from anywhere, so no further action is needed. However, in a real system, this may pose a security risk and should be restricted.
Back in the Instances page, there is a Connect button that gives us everything we need to remote into the Windows VM we have just launched:
From here, we can download a .rdp file which allows us to remote into the machine directly instead of having to specify its DNS name every time. It also shows the DNS name (in case we want to do that anyway), and provides the credentials necessary to access the machine. The username is Administrator; for the password, we need to click the Get Password button and go through an additional step:
The password for the machine can be retrieved by locating the .pem file (downloaded earlier when we created the key pair) and clicking on the Decrypt Password button. Note that you may need to wait a few minutes from instance launch before you can do this.
The password for the machine is now available and can be copied:
Now that we have everything we need, let’s remote into the VM. Locate the .rdp file downloaded earlier, and run it:
You are then prompted for credentials:
By default, Windows will try to use your current ones, so opt to “Use a different account” and specify the credentials of the machine retrieved in the earlier steps.
Bypass the security warning (we’re grown-ups, and know what we’re doing… kind of):
And… we’re in!
If you’re not planning to use the VM, don’t forget to stop or terminate it to avoid incurring unnecessary charges:
The VM will sit there in Terminated state for a while before going away permanently.
This article is based on Visual Studio 2017 Version 15.7 Preview 2. Although it’s nice to get a glimpse of good things to come, keep in mind that it’s not production-ready yet and that things may change.
With the current version of Visual Studio 2017, which is 15.6.5, you have to have really good naming to be able to look at Test Explorer and figure out what your tests actually do:
That’s because the tests are grouped based on their outcome, i.e. whether they’ve passed, failed, or not run at all.
But that’s going to change in Visual Studio 2017, where Test Explorer groups tests based on the more logical hierarchy of project, namespace, class and method:
This is also very handy because you can run a certain group of tests (e.g. tests in a specific class, or tests in a specific namespace), directly from Test Explorer, rather than having to do this by right-clicking the test code and using the context menu (which isn’t very intuitive for newer developers).
This is a small but significant improvement towards making Test Explorer more usable. It is also yet another change that brings Visual Studio closer to ReShaper in terms of functionality.
"You don't learn to walk by following rules. You learn by doing, and by falling over." — Richard Branson