Who would have thought that generating identifiers for data is hard? In line of business applications, most of the time it is sufficient to simply rely on a database’s autoincrement functionality to generate new primary keys. However, as a system scales and inevitably evolves into a distributed architecture, the database can quickly become a bottleneck.

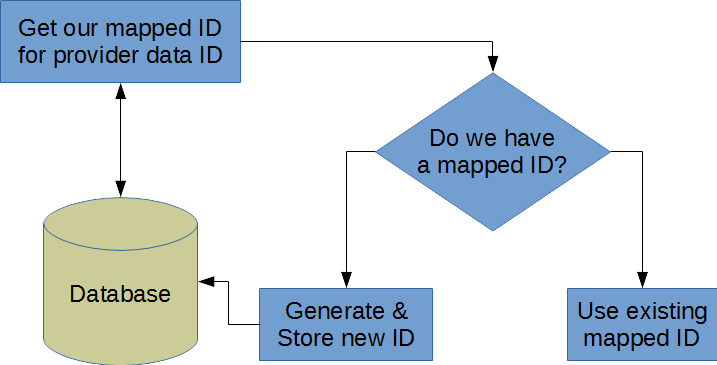
This can easily be a problem when you’re accepting hideous amounts of user-generated content like Facebook and Twitter do. However, it is even more of a burden when you’re receiving data from a provider and need to map their IDs to yours. Each time you receive data, you need to check if their ID is mapped, and if not, you have to generate an ID – so you have to hit the database table twice. You can use a stored procedure to perform this logic in one round trip, but you’ll still have a performance problem as contention on the table increases.
Jeremiah Peschka’s 2012 article, “The Trouble with Keys“, is an excellent summary of why distributed ID generation is hard. In short, generating IDs in a database causes a bottleneck, whereas using something like GUIDs (aside from being longer and a little more inconvenient to pass around e.g. in a URL, and the rare but real potential for collisions) will cause performance issues at the database due to their random nature, because hard disks work best with sequential data.
The solution he proposes is to use a combination of timestamp, worker/machine identifier and sequence number:

The timestamp is the number of milliseconds since an arbitrary time in the past. The worker identifier is anything that is different for each running instance of the ID generator; it could be a MAC address (assuming you’re running not more than one per machine), or even just an arbitrary number. The sequence number is a small (8- or 16-bit) counter that resets every millisecond. Thus, each ID you generate will be unique at different points in time (because of the combination of timestamp and sequence number) and at different machines (because of the worker identifier). The resulting ID is a 128-bit number, which fits in the C# decimal data type and SQL Server’s DECIMAL data type.
Jeremiah Peschka created a library called Rustflakes which generates ID according to this concept. It is based on earlier implementations of the same algorithm by Twitter and Boundary. You can install Rustflakes via NuGet:
Install-Package RustFlakes
The example at the RustFlakes homepage is obsolete and does not work, but this little code will quickly get you generating IDs in no time:
var workerId = new byte[] { 0, 1, 2, 3, 4, 5 };
var idGenerator = new BigIntegerOxidation(workerId);
var id = idGenerator.Oxidize();
The naming is a little bit funny, but basically you create an oxidation (ID generator) instance, and you call Oxidize() to generate the IDs.
If you want to use a MAC address for the workerId, you can use this code adapted from this StackOverflow answer:
var macAddr = NetworkInterface.GetAllNetworkInterfaces()
.Where(nic => nic.OperationalStatus == OperationalStatus.Up)
.Select(nic => nic.GetPhysicalAddress().GetAddressBytes())
.FirstOrDefault();
var workerId = macAddr;
The BigIntegerOxidation is an ID generator that takes a 6-byte worker ID as input and generates a huge ID. However, there are others:
| Generator | Input (Worker) ID | Output (Generated) ID | Timestamp portion |
| BigIntegerOxidation | byte[] | System.Numerics.BigInteger | 64-bit |
| DecimalOxidation | uint | decimal | 48-bit |
| SqlServerBigIntOxidation | ushort | long | 32-bit |
| UInt64Oxidation | ushort | ulong | 32-bit |
You can see the difference between these generators by generating a lot of IDs in a loop:
var idGenerator = new BigIntegerOxidation(workerId);
//var idGenerator = new DecimalOxidation(1);
//var idGenerator = new SqlServerBigIntOxidation(1);
//var idGenerator = new UInt64Oxidation(1);
while (true)
{
var id = idGenerator.Oxidize();
Console.WriteLine(id);
}
Now, when you’re picking which ID generator to use, you have to be careful, because for each of these, there is a catch. The most important thing to keep in mind is that the shorter (in bits) the ID, particularly its timestamp portion, the sooner it will run out. If you run the above loop and watch the rate at which the digits turn, you can make a rough calculation of how long it will last – but keep in mind that this is relative to the epoch, which in Rustflakes is 1st January 2013.
BigIntegerOxidationgenerates numbers that internally use 13 bytes (104 bits). Although technically these should fit in a 128-bitdecimal, in practice they don’t, because their actual value is greater thandecimal.MaxValue. You can pass in an arbitrary epoch to theBigIntegerOxidationconstructor which will make the number smaller and it will possibly convert, but you run a serious risk of exceedingdecimal.MaxValuefast (the default epoch is just under 4 years old, and we don’t know how long agodecimal.MaxValuewas exceeded).DecimalOxidationgenerates 128-bitdecimals, but they’re internally generated as only 96-bit values. This should give you several years of operation, but it’s less than what you’d expect with the full 128 bits.UInt64OxidationandSqlServerBigIntOxidationhave only a 32-bit timestamp portion. These will likely restart in a matter of weeks.