This article shows how you can run the same unit test multiple times with different input data, using NUnit.
A Simple Scenario
Before we can learn about data-driven testing using NUnit, we need some actual logic to test. Let’s use the following class for this purpose:
public class PriceCalculator
{
private decimal adultPrice;
public PriceCalculator(decimal adultPrice)
{
this.adultPrice = adultPrice;
}
public decimal CalculatePrice(int age)
{
decimal multiplier = 0.0m;
if (age >= 5 && age < 16) // 5 to 15: half price
multiplier = 0.5m;
else if (age >= 16 && age < 60) // 16 to 59: full price
multiplier = 1.0m;
else if (age >= 60) // 60+: half price
multiplier = 0.5m;
return this.adultPrice * multiplier;
}
}
So, here we have a scenario where we have something to sell (whatever it is), and certain age ranges get discounts. Kids under 5 years of age are free; older kids under 16 pay half price, as do senior citizens from age 60 onwards.
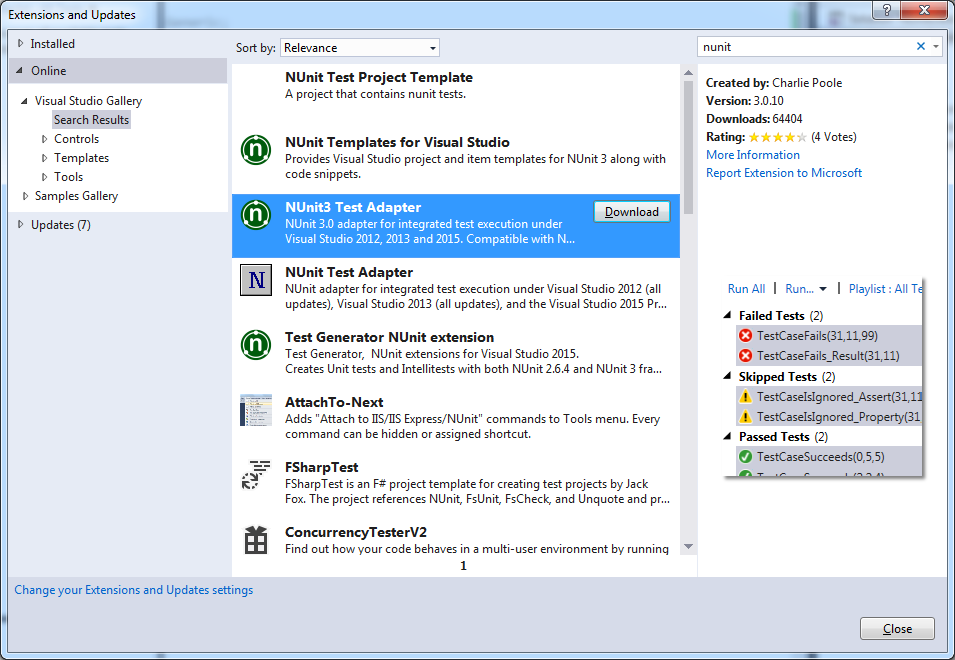
If you want to run NUnit unit tests from within Visual Studio, make sure you have the NUnit Test Adapter. You can get it from Tools menu -> Extensions and Updates…:
Plain Old Unit Tests
To test this, you’d have to write several unit tests. One of them could look like this:
[Test]
public void CalculatePriceTest()
{
// arrange
const decimal adultPrice = 10m;
var priceCalculator = new PriceCalculator(adultPrice);
const int age = 10;
// act
decimal actualPrice = priceCalculator.CalculatePrice(age);
// assert
const decimal expectedPrice = 5m;
Assert.AreEqual(expectedPrice, actualPrice);
}
You’d have to write other similar tests to cover the various age ranges and edge cases (e.g. making sure that age boundaries are inclusive or exclusive as needed).
Copying this test code and varying the input data is a bit of a hassle and not quite DRY. An alternative could be to set up a list with the input data and expected result and iterate over it. That’s not necessary, because NUnit gives us a way to do this out of the box.
The TestCase Attribute
NUnit provides a feature called Parameterized Tests. These provide two mechanisms that allow you to easily run the same test with multiple input data.
The first of these is the [TestCase] attribute. This replaces the [Test] attribute we used before, and provides input data to pass to the test method via parameters:
[TestCase(1, 0)]
[TestCase(10, 5)]
[TestCase(20, 10)]
[TestCase(70, 5)]
public void CalculatePriceTest(int age, decimal expectedPrice)
{
// arrange
const decimal adultPrice = 10m;
var priceCalculator = new PriceCalculator(adultPrice);
// act
decimal actualPrice = priceCalculator.CalculatePrice(age);
// assert
Assert.AreEqual(expectedPrice, actualPrice);
}
This can actually be simplified further by using the ExpectedResult named parameter, and replacing the Assert with a simple return statement:
[TestCase(1, ExpectedResult = 0)]
[TestCase(10, ExpectedResult = 5)]
[TestCase(20, ExpectedResult = 10)]
[TestCase(70, ExpectedResult = 5)]
public decimal CalculatePriceTest(int age)
{
// arrange
const decimal adultPrice = 10m;
var priceCalculator = new PriceCalculator(adultPrice);
// act
decimal actualPrice = priceCalculator.CalculatePrice(age);
// assert
return actualPrice;
}
Note: technically we should declare the expected results as decimals in this case, such as ExpectedResult = 0m. However, the attribute doesn’t seem to allow it. Integers work just fine.
The TestCaseSource Attribute
The [TestCase] attribute works great when you want to run the same test against a few different combinations of input data and expected results. However, it can still get very tedious for very exhaustive tests with a lot of input data.
A more fitting technique for such scenarios is to use the [TestCaseSource] attribute:
[TestCaseSource("TestCases")]
public decimal CalculatePriceTest(int age)
{
// arrange
const decimal adultPrice = 10m;
var priceCalculator = new PriceCalculator(adultPrice);
// act
decimal actualPrice = priceCalculator.CalculatePrice(age);
// assert
return actualPrice;
}
The [TestCaseSource] attribute takes the name of a public static property which will provide the input data (i.e. the same data that we passed in to the [TestCase] attribute earlier). You can use this to load the data from arbitrary sources such as databases, files, etc.
There are a number of ways of working with the [TestCaseSource] attribute (refer to the documentation), but a straightforward way to work with it is to use the TestCaseData class. You can provide it with any input data as well as an expected result. For instance, say we have the following CSV file mapping age to expected price, for ages between 0 and 99:
0,0 1,0 2,0 3,0 4,0 5,5 6,5 7,5 8,5 9,5 10,5 11,5 12,5 13,5 14,5 15,5 16,10 17,10 18,10 ...
We can write a property that reads this and provides the necessary test case data as follows:
public static List<TestCaseData> TestCases
{
get
{
var testCases = new List<TestCaseData>();
using (var fs = File.OpenRead(@"C:\test.csv"))
using (var sr = new StreamReader(fs))
{
string line = string.Empty;
while (line != null)
{
line = sr.ReadLine();
if (line != null)
{
string[] split = line.Split(new char[] { ',' },
StringSplitOptions.None);
int age = Convert.ToInt32(split[0]);
decimal expectedPrice = Convert.ToDecimal(split[1]);
var testCase = new TestCaseData(age).Returns(expectedPrice);
testCases.Add(testCase);
}
}
}
return testCases;
}
}
You can see the power of this approach when you run a hundred tests in the bat of an eyelid:
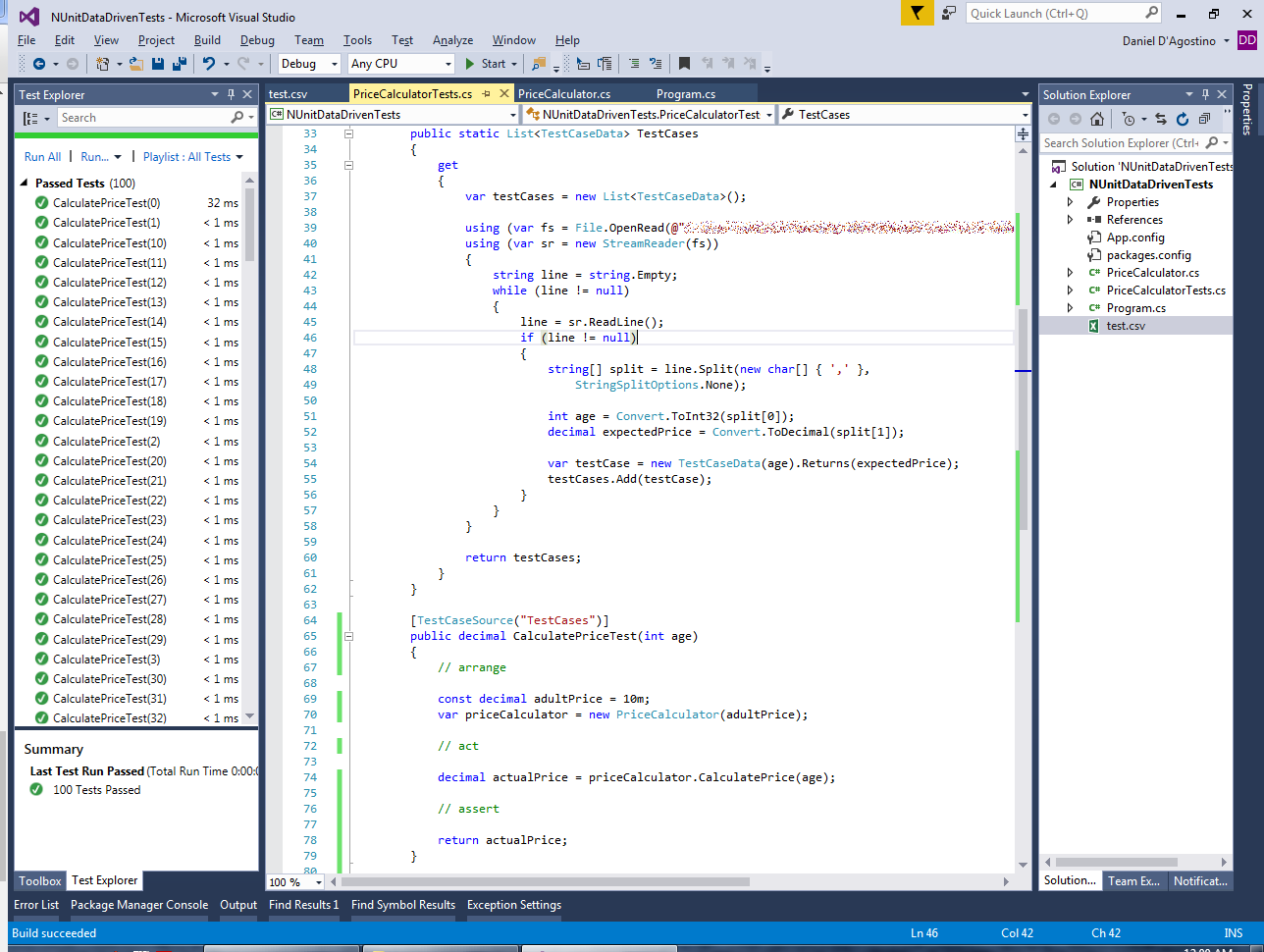
The first test takes a small performance penalty as the test data is loaded. But that’s a small price to pay for the development time saved in writing unit tests.