Data Annotations are attributes which you can apply to properties in order to specify validity constraints, such as required fields, string lengths, or numeric ranges. They are quite useful to use as part of bigger frameworks such as ASP .NET MVC or WPF. This article shows very simple examples of their usage in a console application.
Adding Data Annotations
In order to add data annotations, you’ll first need to add a reference to System.ComponentModel.DataAnnotations.dll. Once that is done, add a simple class and decorate the properties with attributes from that namespace:
public class Person
{
[Required]
public string Name { get; set; }
[Range(18, 60)]
public int Age { get; set; }
}
There are many predefined attributes you can use, and it is also possible to create your own by creating a class that derives from ValidationAttribute.
In this example we’re using the RequiredAttribute, which causes validation to fail if the string is null, empty, or whitespace; and the RangeAttribute, which requires a number to be within a specified range.
Property Validation
We can validate a single property on our Person object by using the Validator.TryValidateProperty() method:
static void RunValidateProperty(string value)
{
var person = new Person();
var context = new ValidationContext(person) { MemberName = "Name" };
var results = new List<ValidationResult>();
var valid = Validator.TryValidateProperty(value, context, results);
}
In order to do this, we need to supply three things:
- A ValidationContext which specifies the property to validate and the object it belongs to;
- A collection of ValidationResult, which is a glorified error message; and
- A value for the property that will be checked for validity.
The fact that any value can be checked for a given property makes TryValidateProperty() particularly useful to use in property setters, such as in this example.
Let’s see what happens when we try validating the Name property (remember, it’s marked as Required) with a value of null:

In this case TryValidateProperty() returned false, and a ValidationResult was added to the results collection with the message “The Name field is required.”.
Now if we give it a valid string, it behaves quite differently:
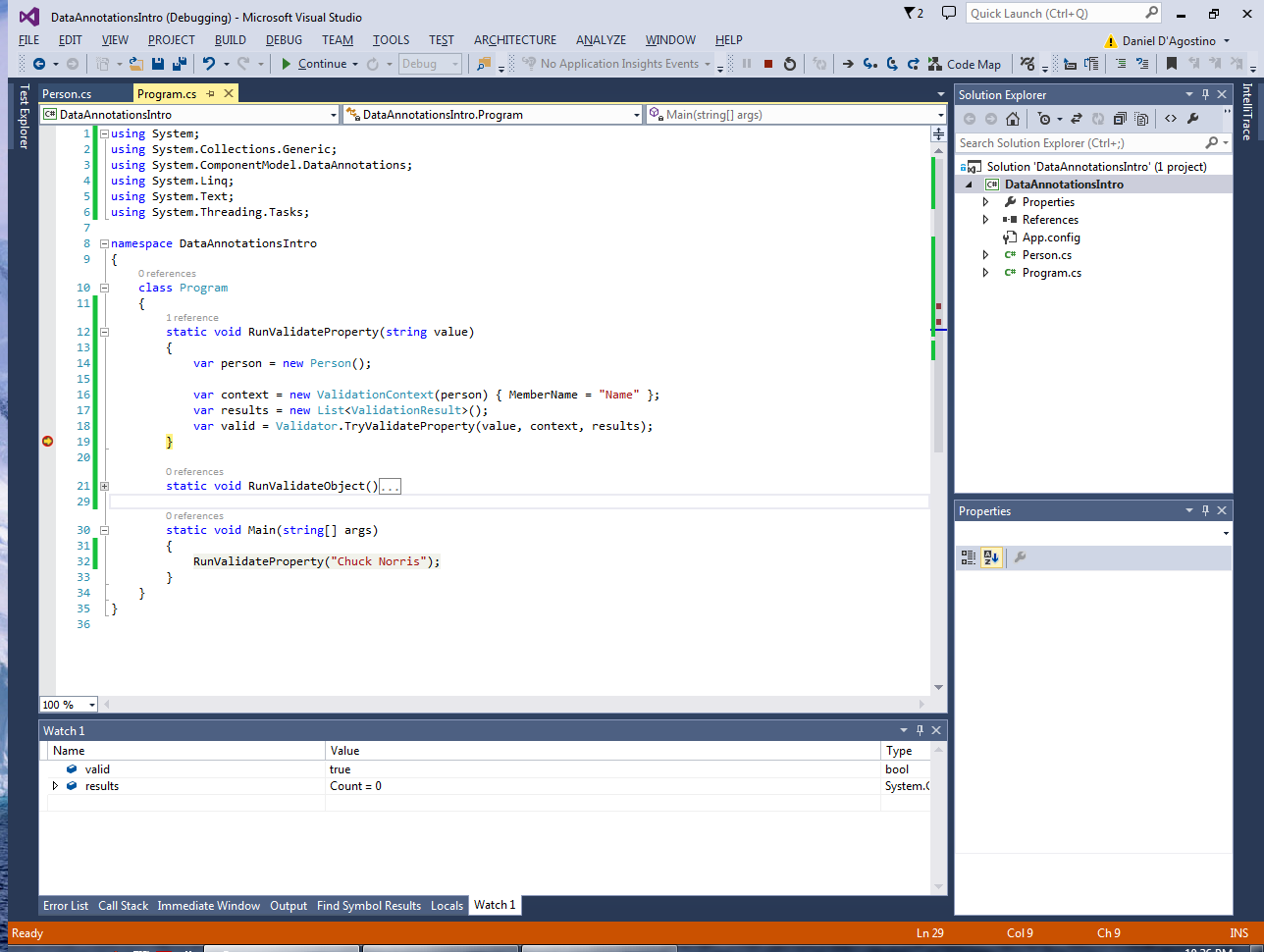
TryValidateProperty() returned true, and there are no ValidationResults to report.
Object Validation
While validating a single property is quite useful (e.g. while a particular field is being edited), it is often useful to validate every property in a class (e.g. when submitting data in a form).
This functionality is provided thanks to Validator.TryValidateObject():
static void RunValidateObject()
{
var person = new Person();
var context = new ValidationContext(person);
var results = new List<ValidationResult>();
var valid = Validator.TryValidateObject(person, context, results);
}
Let’s try it out and see what happens:

You’ll notice that validation failed and we got a ValidationResult for the Name field. But we also have an Age property, which is supposed to be between 18 and 60, and yet it still has its default value of zero. Why didn’t that property fail validation too?
See, this happens due to an awkward default behaviour of TryValidateObject(), which by default only validates fields which are marked as Required. In order to factor in other attribute types in the validation, you need to use a different overload of TryValidateObject() which takes a boolean at the end, and set it to true:
static void RunValidateObject()
{
var person = new Person();
var context = new ValidationContext(person);
var results = new List<ValidationResult>();
var valid = Validator.TryValidateObject(person, context, results, true);
}
And now, the result is much more reasonable:

Limitations
Using attributes for validation is a very useful concept. It allows you to simply attach metadata to properties, and let the validation logic consume those attributes when necessary.
However, data annotations also carry with them the limitations of attributes. Among these is the fact that attributes can only have static values, and so it is not possible to incorporate logic into them (e.g. to have them depend on the value of another property).
Source Code
Check out the source code for this article at the Gigi Labs BitBucket repository.






