This article was originally posted at Programmer’s Ranch on 29th August 2013. The version migrated here is mostly the same except for minor updates and a brand new screenshot of the latest GOG installer for Ultima 1.
It’s no secret that I’m a long-time fan of the Ultima series of games. My most significant contribution to the Ultima fan community was running Dino’s Ultima Page, a news and information hub for the community, for over a decade.
Ultima insipired such a great following that hundreds of fan-made remakes, tools and other projects appeared over the years. Many remakes were intended to be mods of games such as Dungeon Siege or Neverwinter Nights. Among other things, talented developers found ways to understand the data files of the games (including the graphics, savegames, maps, etc). This resulted in several useful tools (savegame editors, map viewers, etc), but more importantly, it allowed people to create new game engines using the original data files, with the intention of allowing the games to be played on modern operating systems. The first of these was Exult (an Ultima 7 engine), but over the years, projects appeared for most Ultimas – such as Pentagram for Ultima 8, or Nuvie for Ultima 6.
This article describes the process of reverse engineering, i.e. how to try to make sense of data files given the data files and nothing else. We will be looking at the savegame format of Ultima 1. Although Ultima 1 is not free, you can get the entire first Ultima trilogy from Good Old Games for a few bucks. Ultima 1 is a great choice to start reverse engineering because it’s relatively simple – the savegame file is only 820 bytes long and is uncompressed. This made sense for me as when I started this project I was still a budding programmer, and it also made sense because there was very little knowledge about the U1 formats around, whereas the later games had been studied in depth. Reverse engineering is a bit of an advanced topic so feel free to skip it if you feel lost, but it’s also a very interesting topic.
So first thing you need to do is install Ultima 1. If you got it off Good Old Games, it conveniently comes with DOSBox, allowing you to play it under modern operating systems:

After launching the game, you will find yourself in the main menu.
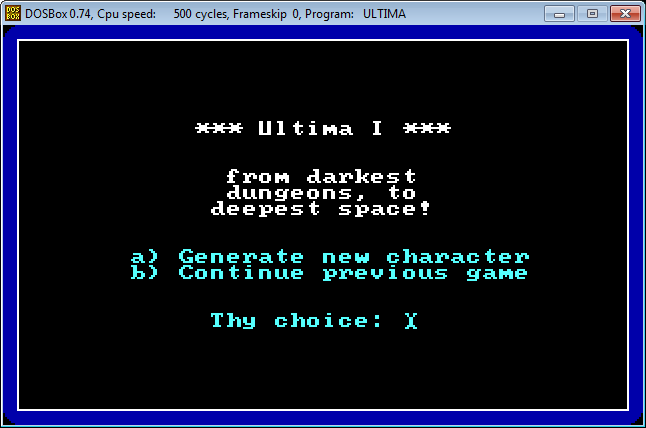
Press ‘a’ to go through the character creation process.
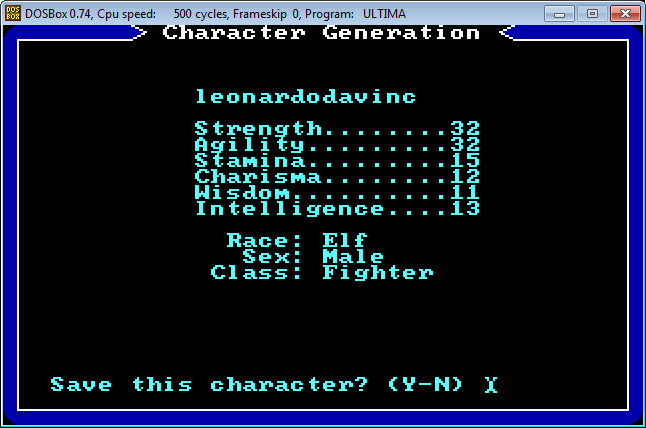
Once you have selected your attributes and saved your character, you find yourself back in the main menu. In the Ultima 1 folder, you should notice a new file called PLAYER1.U1:

That’s the savegame file we’ll be messing around with. You can use a hex editor to take a glimpse of its contents. Personally I like XVI32 because it’s pretty lightweight and even allows you to edit hex entries.

This might look like gibberish, but you can already notice a few things. The first 14 bytes in the savegame file are reserved for the player’s name. Knowing the stats you chose during character creation (strength 32, agility 32, stamina 15, charisma 12, wisdom 11 and intelligence 13), you can also spot them in hex on the second line (20, 20, 0F, 0C, 0B, 0D). Windows Calculator has a Programmer mode that is quite useful for switching between decimal and hex:

A good way of decoding more parts of the savegame file is interacting with the game itself. Start the game. The world view looks like this:

Keep a copy of your savegame file at this point. If you move around a bit and save the game, you should at the very least observe changes in your character’s X- and Y-coordinates:
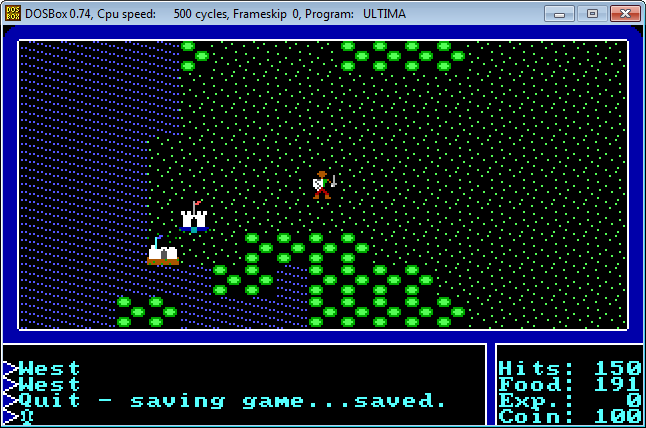
You can manually check which bytes in the savegame file changed. I found it more useful to write a hex diff tool that actually highlights the bytes that changed:
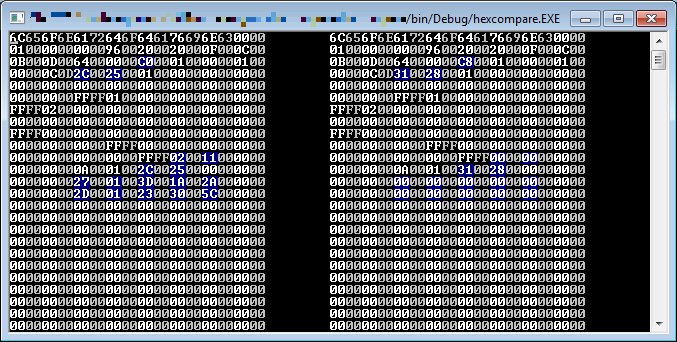
As you can see, it’s not so simple: there are many things that might change, including food. However, you can choose your moves carefully (e.g. 2 steps west, 3 steps north) so that you can then spot which bytes have changed that much and determine which are the world coordinates.
Another way of learning more about the savegame file is by actually tampering with it. Using XVI32, I changed the byte after ’96’ from 00 to 13:

After running the game, note how the Hits shot up from 150 to 5014:

That makes a bit of sense: the 96 (hex) we saw earlier corresponds to 150 in decimal – the original value of Hits. But why did it become 5014 when we tweaked the byte after it?
It’s because DOS games like this stored values as 16-bit integers in little endian format (i.e. the bigger byte is the second one). So if we have the value we tweaked, i.e. 96 13, that’s actually (13 * 100) + 96 (all hex), which results in 5014 (decimal).
Isn’t that neat? Reverse engineering requires a lot of time and patience, but it’s a bit like fitting together the pieces of a jigsaw puzzle. After a while you might end up understanding a good chunk of the data files:

Once you understand the data files (which also includes map and graphics files), you can then proceed to write all sorts of tools and stuff. I had called this project U1Revenge (Ultima 1 Reverse Engineering Effort) and wrote a map viewer and was working on an engine for it. Although I stopped working on it, I did release a couple of demos, the latest of which you can grab from the project page.

Reverse engineering is certainly not a new art. The book Masters of Doom describes how fans of DOOM would hack the game’s map files to create their own level editors. Many games have similarly been studied, and a wealth of knowledge is available today. Reverse engineering is not just an achievement; it is a glimpse of history, and helps to understand how games were created even before we were born. The following links provide further reading:
- Dino’s Guide to Ultima 1 – additional technical info on Ultima 1
- Ultima IV Technical Info – technical info on Ultima 4; helps understand DOS graphics
- DOS Game Modding Wiki – a wealth of technical info about many DOS games
- Reverse engineering guide – basics on reverse engineering, hex and stuff